c++ STL
STL 逆向方法论
- 识别 STL 容器类型
- 识别 STL 容器操作
- 提取 STL 容器中的数据
逆向 STL 主要的问题:
- 缺少符号,无法判断 STL 容器类型 (主要困难)
- STL 内部数据结构复杂,难以提取数据
- 优化使大量 stl 函数被 inline
方法:解析 STL 容器内存数据,从内存数据角度判断容器类型,提取容器内容判断函数操作。
常见 STL 容器
序列容器
- vector
- Deque
- List
- String
关联容器
- Pair
- Map
- Set
- MultiMap / MultiSet
无序关联容器:unordered_map
C++ STL关联式容器是什么?
此类容器在存储元素值的同时,还会为各元素额外再配备一个值(又称为“键”,其本质也是一个 C++ 基础数据类型或自定义类型的元素),它的功能是在使用关联式容器的过程中,如果已知目标元素的键的值,则直接通过该键就可以找到目标元素,而无需再通过遍历整个容器的方式。
弃用序列式容器,转而选用关联式容器存储元素,往往就是看中了关联式容器可以快速查找、读取或者删除所存储的元素,同时该类型容器插入元素的效率也比序列式容器高。
常见 STL 容器适配器
容器适配器是一个封装了序列容器的类模板,它在一般序列容器的基础上提供了一些不同的功能。之所以称作适配器类,是因为它可以通过适配容器现有的接口来提供不同的功能。
其实,容器适配器中的“适配器”,和生活中常见的电源适配器中“适配器”的含义非常接近。我们知道,无论是电脑、手机还是其它电器,充电时都无法直接使用 220V 的交流电,为了方便用户使用,各个电器厂商都会提供一个适用于自己产品的电源线,它可以将 220V 的交流电转换成适合电器使用的低压直流电。
从用户的角度看,电源线扮演的角色就是将原本不适用的交流电变得适用,因此其又被称为电源适配器。
举一个例子,假设一个代码模块 A,它的构成如下所示:
class A{
public:
void f1(){}
void f2(){}
void f3(){}
void f4(){}
};
现在我们需要设计一个模板 B,但发现,其实只需要组合一下模块 A 中的 f1()、f2()、f3(),就可以实现模板 B 需要的功能。其中 f1() 单独使用即可,而 f2() 和 f3() 需要组合起来使用,如下所示:
class B{
private:
A * a;
public:
void g1(){
a->f1();
}
void g2(){
a->f2();
a->f3();
}
};
可以看到,就如同是电源适配器将不适用的交流电变得适用一样,模板 B 将不适合直接拿来用的模板 A 变得适用了,因此我们可以将模板 B 称为 B 适配器.
容器适配器也是同样的道理,简单的理解容器适配器,其就是将不适用的序列式容器(包括 vector、deque 和 list)变得适用。容器适配器的底层实现和模板 A、B 的关系是完全相同的,即通过封装某个序列式容器,并重新组合该容器中包含的成员函数,使其满足某些特定场景的需要。
stack(STL stack)容器适配器:采用默认的 deque 基础容器
queue容器适配器:其底层使用的基础容器选择默认的 deque 容器
priority_queue :vector
逆向时处理容器适配器只需要用底层容器来处理即可
STL 各高级类型dump数据
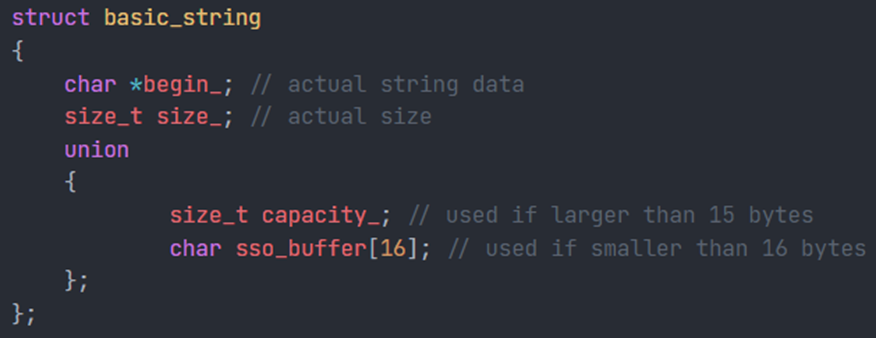
std::string
- 固定长度 32 字节,4 个 dq
- 第一个指针字段指向数据地址
- 第二个 size_t 字段存储字符串长度
内存分布:
IDA dump脚本:
def read_dbg_cppstr_64(objectAddr):
# a easy function for read std:string
# 首地址就是begin指针
strPtr = idc.read_dbg_qword(objectAddr)
result = ''
i = 0
while True:
onebyte = idc.read_dbg_byte(strPtr + i)
if onebyte == 0:
break
else:
result = chr(onebyte)
i += 1
return result
std::stringsteam
可以看作是读写文件
内存分布: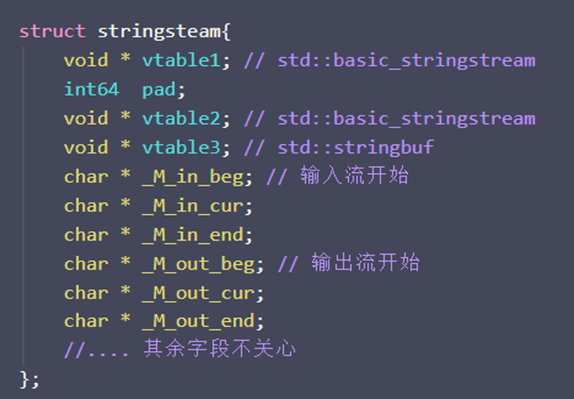
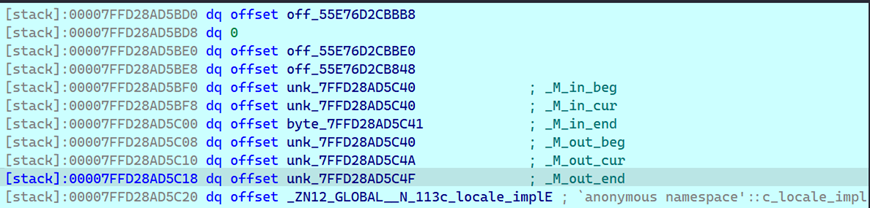
std::vector
- 固定长度 24 字节,3 个 dq
- 第一个指针字段指向数组起始地址
- 第二个指针字段指向数组最后元素地址
- 第三个指针字段指向最大内存地址
内存分布:
IDA dump脚本
def vetor_dump(addr):
ELEMENT_SIZE = 8
data_addr = []
vetor_base = idc.read_dbg_qword(addr + 0x0)
vetor_end = idc.read_dbg_qword(addr + 0x8)
for i in range(vetor_base,vetor_end,ELEMENT_SIZE):
data_addr.append(i)
return data_addr
std::list
- 双向循环链表存储
- 头结构 + 节点结构
- 遍历长度可以用 size 字段确定

内存布局: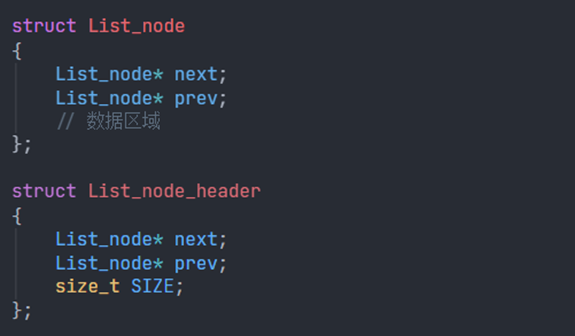
IDA dump 脚本:
def dump_stl_list(p_list_addr):
data_addr = []
list_size = idc.read_dbg_qword(p_list_addr+0x10)
cur_node = p_list_addr
for i in range(list_size):
cur_node = idc.read_dbg_qword(cur_node + 0x0)
data_addr.append(cur_node + 0x10)
std::deque
- 头结构 + 迭代器结构
- 适用 std::deque / std::stack
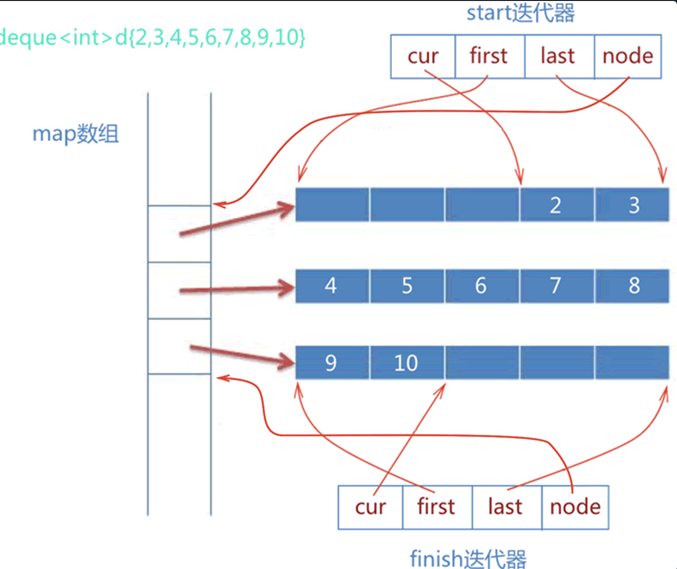
- stl_deque.start.node 确定first map 项位置
- stl_deque.start.last - stl_deque.start.first 确定缓冲区大小
- stl_deque.finish.node 确定last map 项位置
- 对于每一个 map 项:
- start 项,解析 cur, last 区间
- finish 项,解析 start, cur 区间
- 其余项,解析 start, last 区间
内存布局:
IDA dump 脚本:
deque_iter = namedtuple('deque_iter',['cur','first','last','node'])
def parse_iter(addr):
# 解析队列迭代器
cur = idc.read_dbg_qword(addr + 0x0)
first = idc.read_dbg_qword(addr + 0x8)
last = idc.read_dbg_qword(addr + 0x10)
node = idc.read_dbg_qword(addr + 0x18)
return deque_iter(cur,first,last,node)
def dump_deque(addr):
ELEMENT_SIZE = 4 # std::deque<xx> xx 的类型大小来指定
data_addr = []
start_iter = parse_iter(addr + 0x10)
finish_iter = parse_iter(addr + 0x30)
buf_size = start_iter.last - start_iter.first
map_size = start_iter.node
map_finish = finish_iter.node
# 解析第一个缓存数据
for i in range(start_iter.cur,start_iter.last,ELEMENT_SIZE):
data_addr.append(i)
# 解析最后一个缓存数据
for i in range(finish_iter.first,finish_iter.cur,ELEMENT_SIZE):
data_addr.append(i)
# 解析中间缓存数据
for i in range(map_start + 8,map_finish - 8,8):
buf_start = idc.read_dbg_qword(b)
for i in range(buf_start,buf_start + buf_size, ELEMENT_SIZE):
data_addr.append(i)
return data_addr
std::map
- 底层采用 Rb-Tree 实现(红黑二叉树)
- 头结构 + 节点结构
- 用二叉树遍历可提取数据
- 适用 std::map / std::set / std::multimap / std::multiset
内存分布: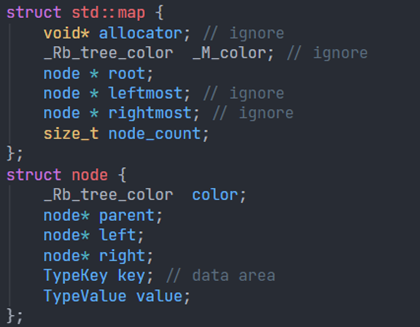
IDA dump 脚本:
def parse_gnu_map_header(address):
root = idc.read_dbg_qword(address + 0x10)
return root
def parse_gnu_map_node(address):
left = idc.read_dbg_qword(address + 0x10)
right = idc.read_dbg_dword(address + 0x10)
data = address + 0x20
return left, right, data
def parse_gnu_map_travel(address):
# address <—— std::map struct address
result = []
worklist = [parse_gnu_map_header(address)]
while len(worklist) > 0:
addr = worklist.pop()
(left, right, data) = parse_gnu_map_node(addr)
if left > 0: worklist.append(left)
if right > 0: worklist.append(right)
result.append(data)
return result
std::unsorted_map
- 底层采用 HashTable 实现
- 头结构 + Bucket 数组 + 节点结构
- 所有节点结构用单链表串联(****dump 只需要遍历单链表)
- 头结构的第三个字段为单链表头
- 适用 **std::**unsorted_map **/ std::**unsorted_set / …
内存布局: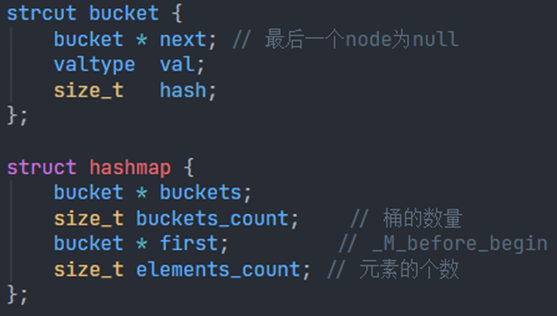
IDA dump 脚本:
def dump_stl_hashmap(addr):
# dump stl hashmap gnu c++ x64
data_addr = []
bucket_addr = idc.read_dbg_qword(addr + 0x10)
node_addr = bucket_addr
while node_addr != 0:
data_addr.append(node_addr + 0x8)
node_addr = idc.read_dbg_qword(node_addr)
return data_addr
std::shared_ptr
第一个指针就是数据指针
内存布局: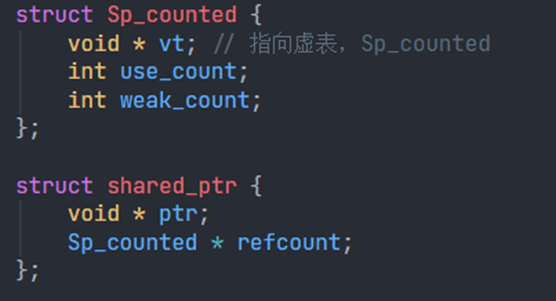
实战部分
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 jaytp@qq.com

