IDA逆向神器
IDA工具介绍
IDA Pro(交互式反汇编器专业版,我们一般简称为IDA)是一款递归下降的反汇编器,由Hex-Rays SA发布,是安全从事人员的必备工具之一。它强大的静态反汇编,反编译功能及动态调试功能让我们分析程序变得简单。它支持数十种CPU指令集其中包括[Intel x86](https://baike.baidu.com/item/Intel x86),x64,MIPS,PowerPC,ARM,Z80,68000,c8051等等,无论是winodws平台下的pe可执行文件,linux平台下的elf文件及ios平台下的Mach-O文件都适用。
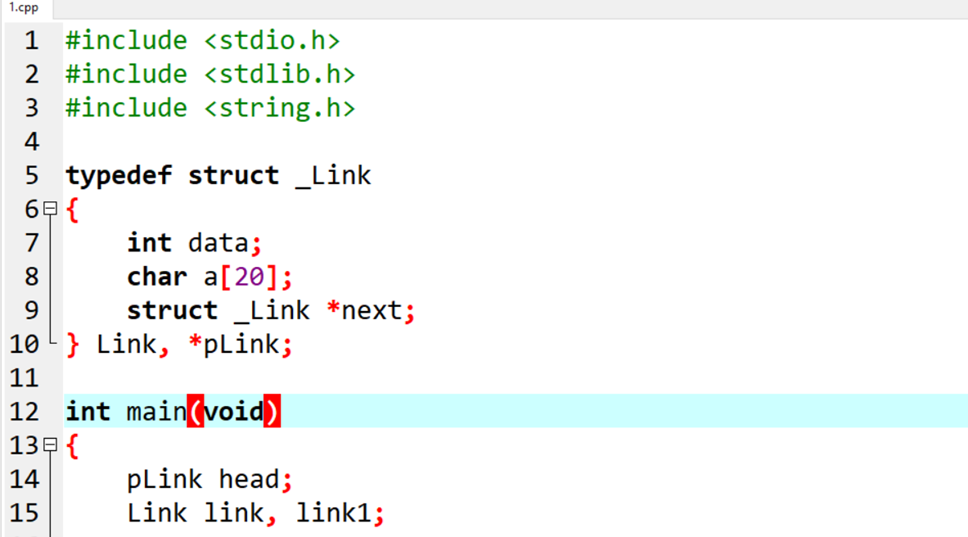
一个简单的C语言程序用作实验。
IDA分为32版本与64版本,这是根据所要反汇编程序的位数来区分的,但其实他们自身都是64位的程序。
根据程序的位数选择对应位数的IDA打开程序。(附件是64位的
一般没有特殊需求,我们直接默认点击OK就好了。
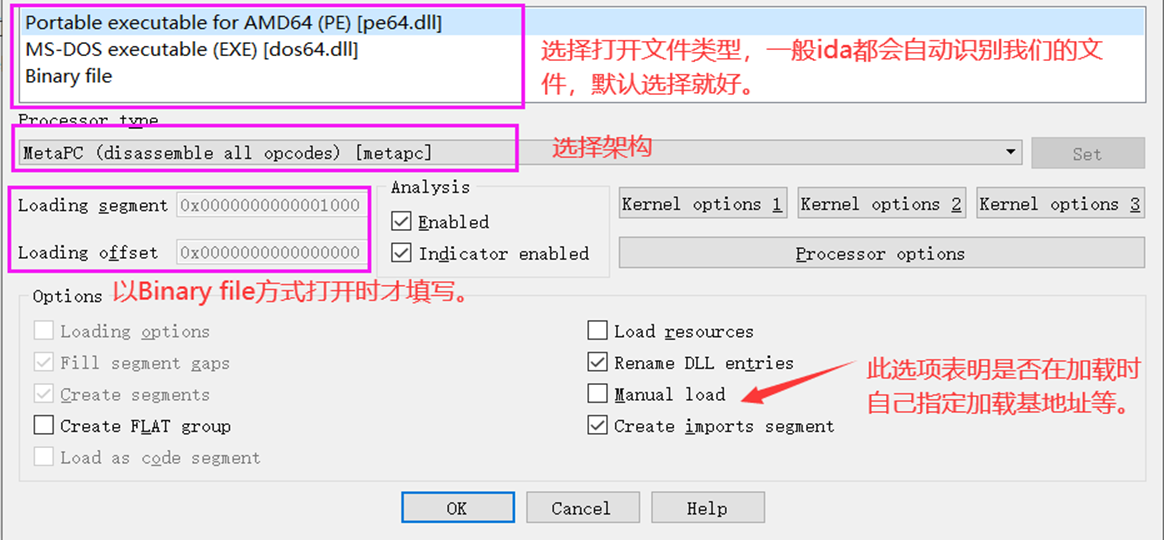
点击Ok后接着的各种提示,如加载对应的pdb符号文件,统统点击否,然后进行来到载入主窗口。
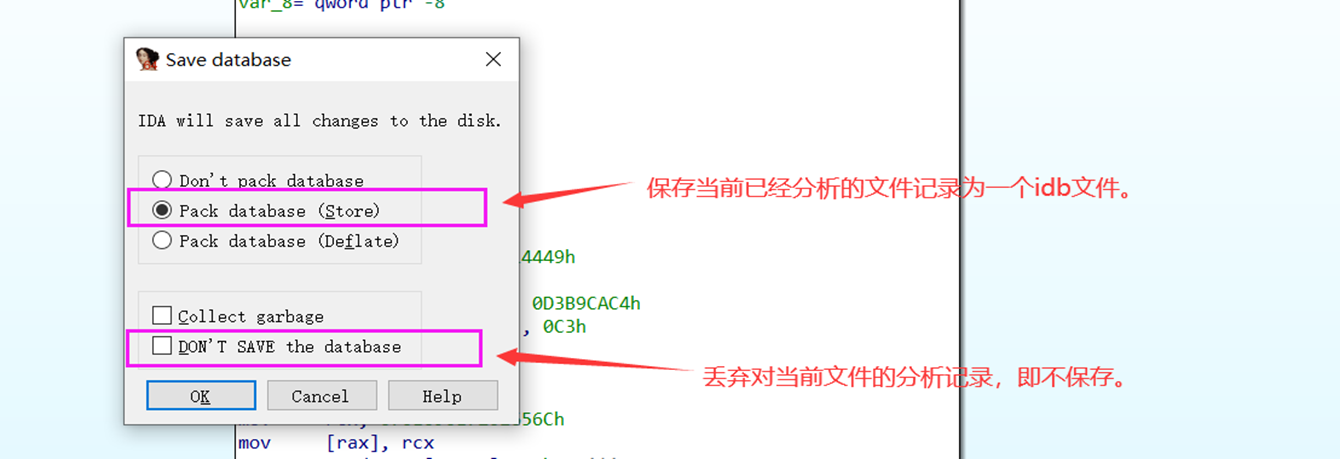
然后再关闭IDA,出现下面的提示框。
一般我我们就选择下面标出的2个选项中的一个即可。第一个保存为了下次分析继续使用,另外一个不保存。
上一步点击保存文件退出后,将该exe文件再次重新载入IDA。
overwrite 重新写入,代表覆盖以前的。
load existing 加载已经存在的,就是直接加载我们之前分析过该程序保存的数据库文件,保存了上次的分析记录方便我们继续分析。

IDA功能界面介绍
流程图界面显示对应的伪代码,此界面下按 / 即可。
Text-view文本视图
切换图形视图和文本视图(点空格键就行)
IDA功能界面介绍
导航栏

- - 蓝色:.text section
- - 深蓝:用户写的函数编译后的代码区
- - 浅蓝:编译器自己添加的函数,像启动函数,异常函数等等..
- - 粉红色:.idata section 有关输入表的一些数据信息
- - 军绿色:.rdata section 纯数据,只读
- - 灰色:为了段对齐而留下的空隙
- - 黑色: 禁区
汇编代码界面注释
一种是Enter comment(快捷键是shift+;)),另一种是Enter repeatable comment(快捷键是;和OD一样)
前一种输入的注释只在该处出现,后一种注释,会在所有交叉参考处出现,如果一个程序位置引用了另一个包含可重复注释的位置,则该注释会在第一个位置回显,且以灰色显示。

伪代码代码界面注释,快捷键 /
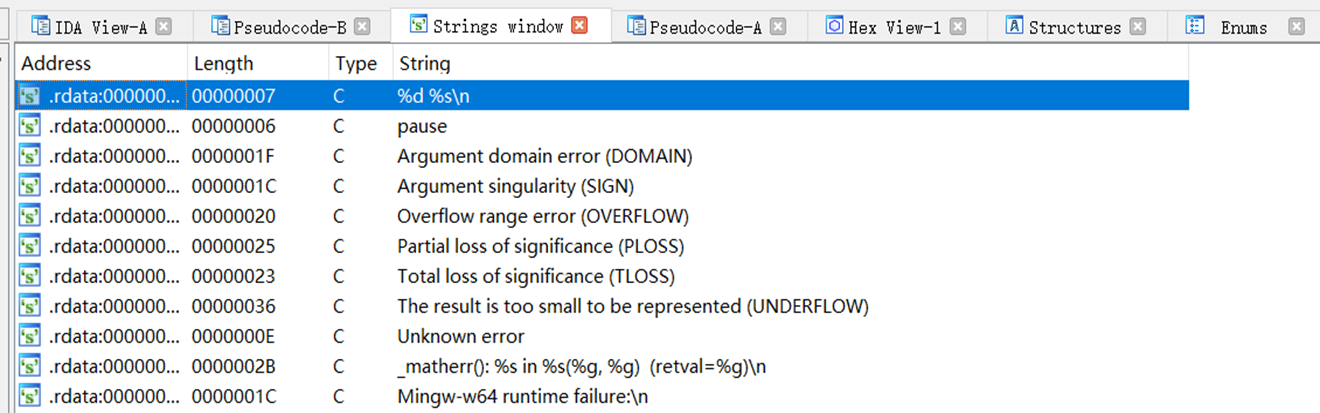
字符串窗口 shift+f12
程序中被IDA解析出来的字符串,当然还有因为未解析出来所以没显示的。
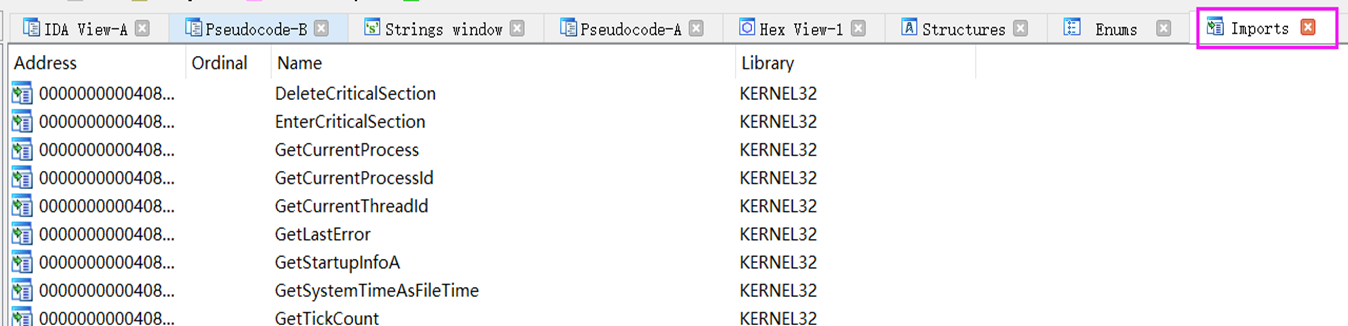
导入表窗口
程序从动态链接库中导入的要使用的函数。
导出表窗口
程序导出给其它程序使用的函数。
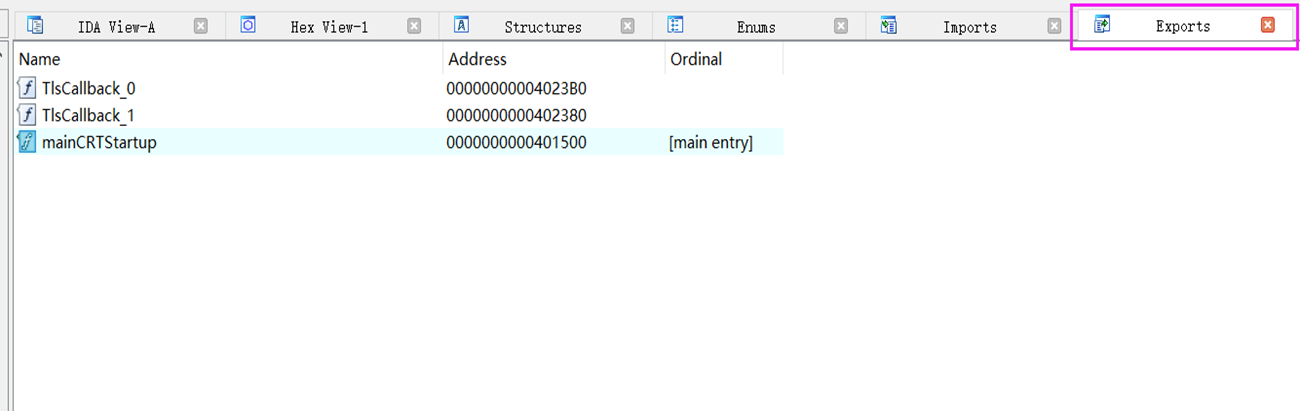
十六进制数据窗口
类似于一个十六进制编辑工具看文件的二进制信息
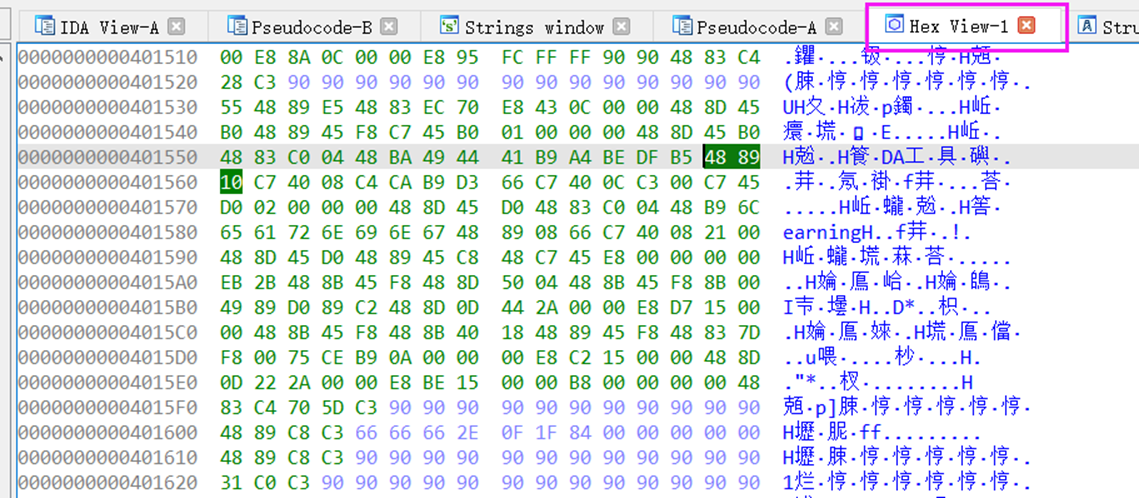
函数窗口
对于ida没有识别出来的函数,统统以sub_函数地址命名。
为了方便,我们还可以直接在函数窗口ctrl+f,然后搜索目标函数。
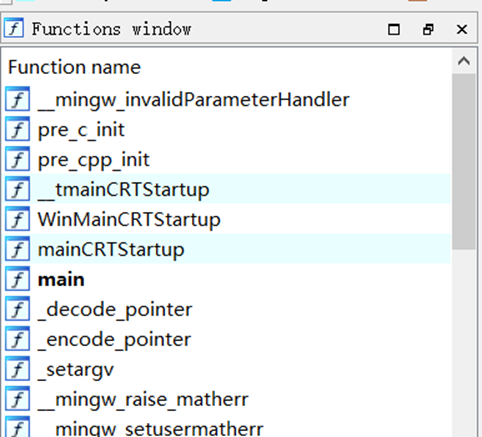
结构体窗口
这里显示了本次分析程序ida中已经定义了的结构体,同时我们也可以在插入创建新的结构体。
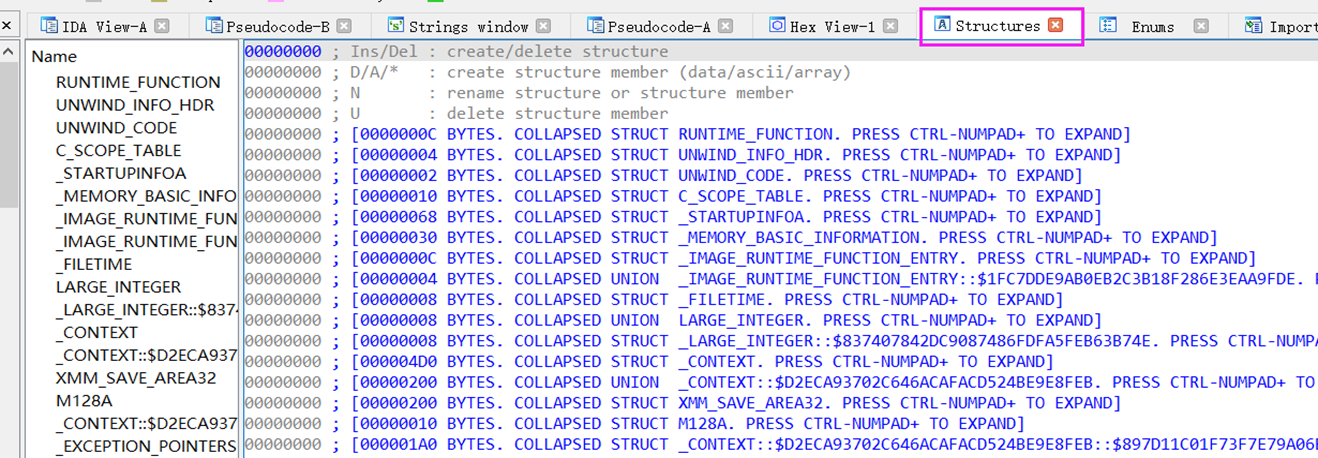
.rdata段中的字符串
用于定义字符串都在一块内存区域,根据这个也是定位找字符串的方法。
如下,.rdata段的字符串信息,最右边的是隐式的可重复注释,指示的那里引用了该字符串。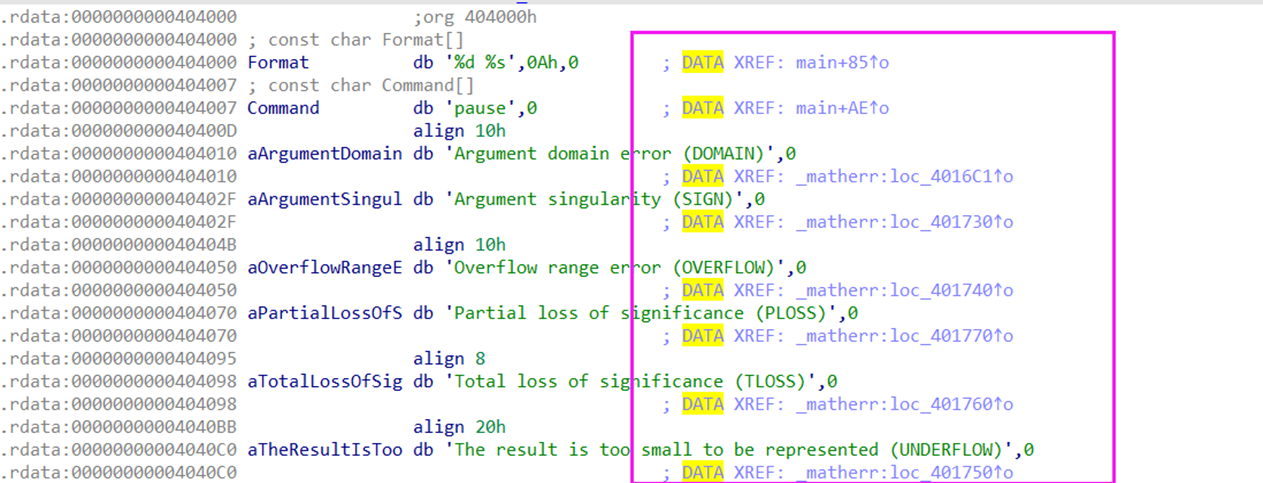
寻找入口点 快捷键 ctrl+e
在IDA载入程序分析完毕后,ctrl+e打开选择程序入口点的窗口,这里可以方便找到程序的入口点及用到的回调函数。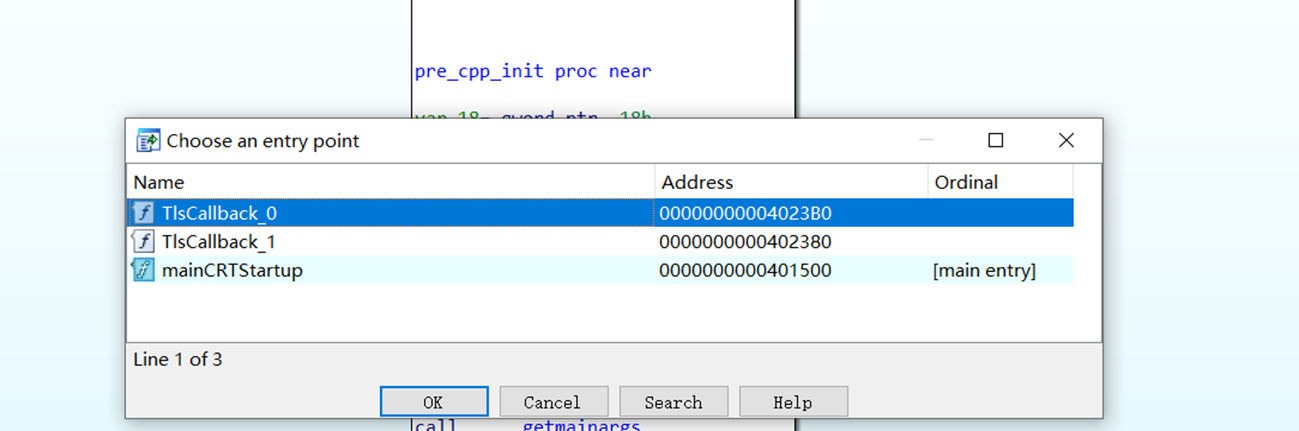
地址跳转 快捷键 G
按下快捷键 G,输入地址后跳转到目的地址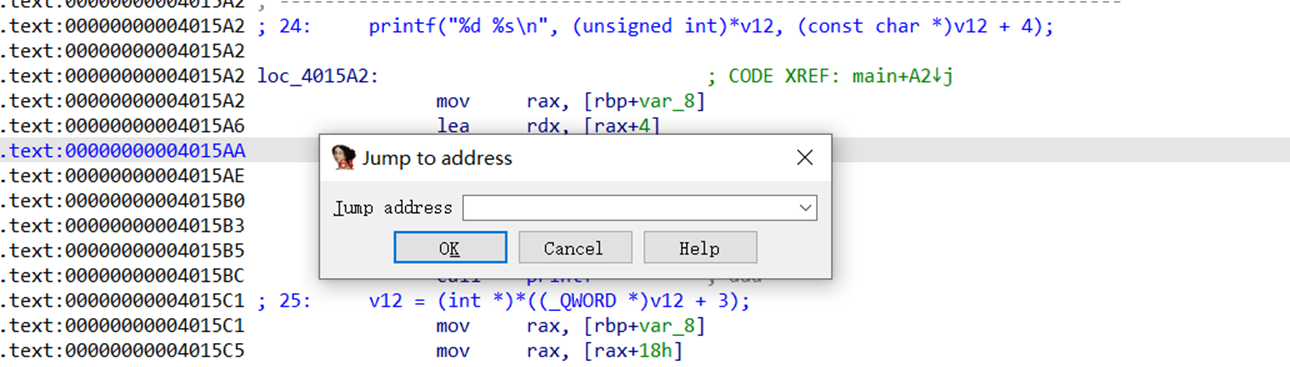
参考重命名 在变量名下按 n
在分析一个程序时,我们可以对一些变量或者函数重命名,改成我们易于我们理解的名字,便于分析程序。
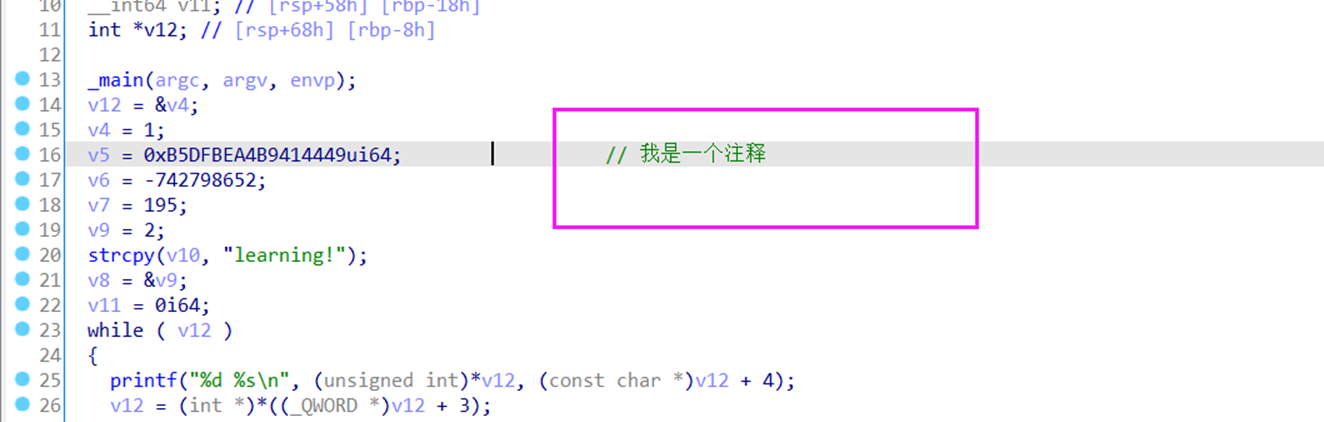
如下,假如我们知道了v12变量是一个计数功能,那我们就可以给他重命名为 count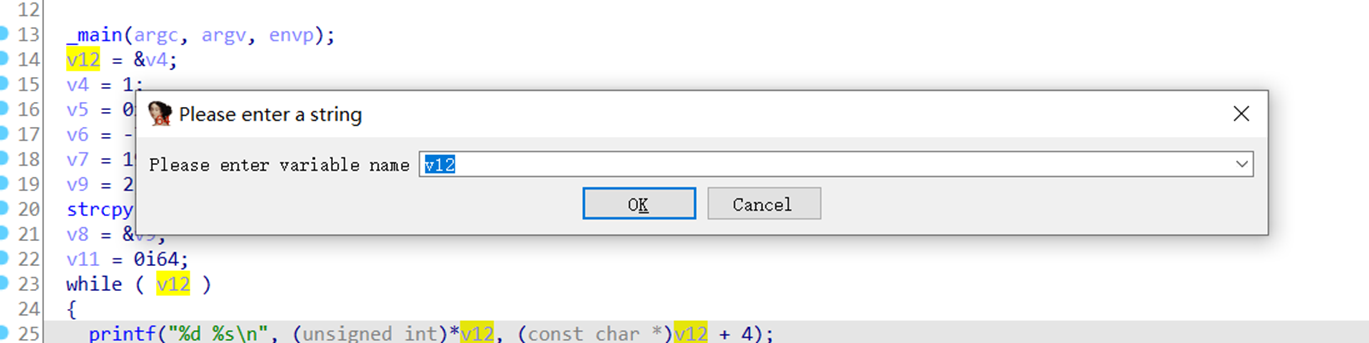
参考类型修改 在变量名下按 y
在分析一个程序时,IDA对一些变量名可能解析的不是很正确,这就需要我们手动去修改变量的类型。
如下所示,在v12变量下按y键后再输入我们要修改的变量类型。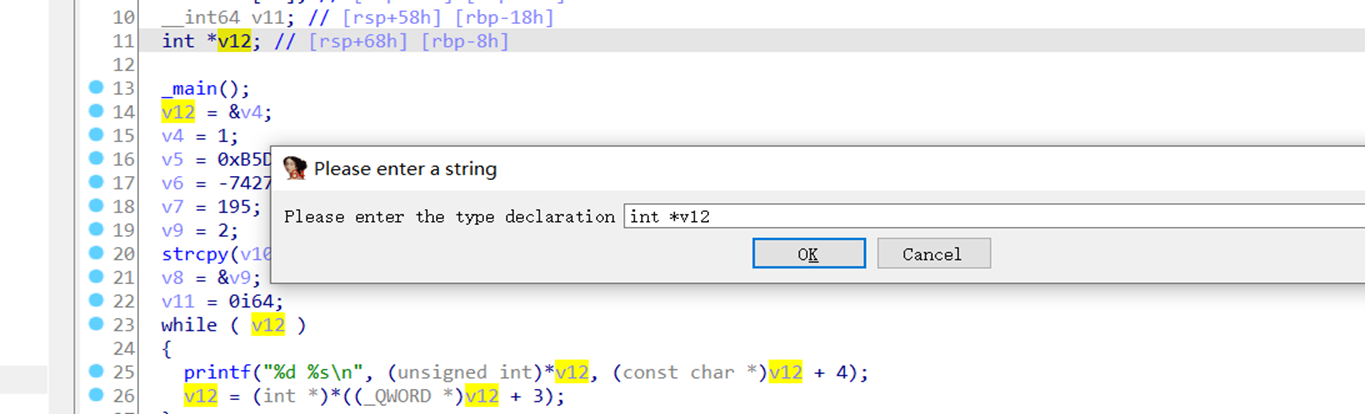
数据转化为代码 在数据开始的地方按 C
在分析一个程序时,有时候因为栈帧或者其它原因使IDA不能反编一个函数有问题,又或者程序有smc,我们在手动对数据解码后,接着在解码数据开始的地方按C键就将数据转化为代码了。如下所示,我们在57h的地方按下C键,IDA就会自动对数据解析成代码了。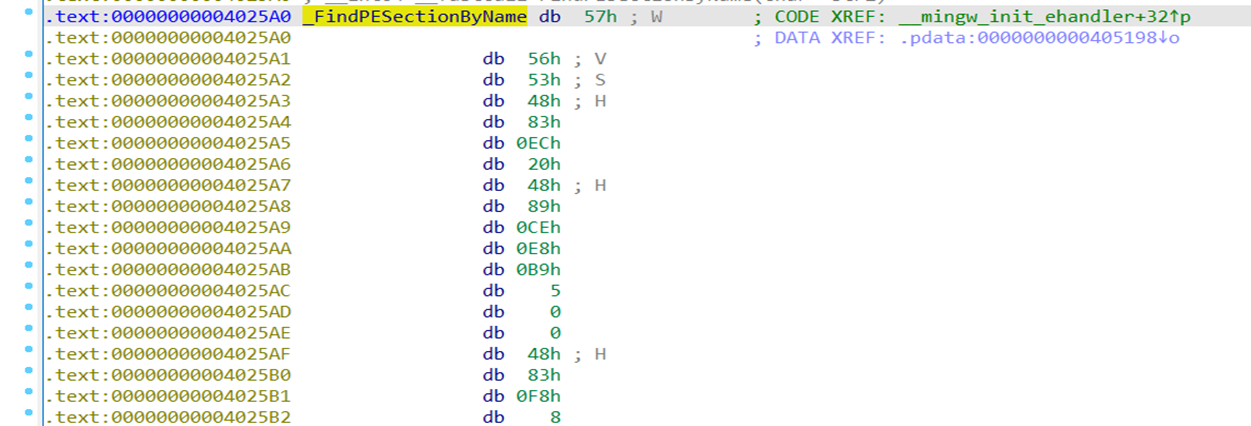
创建函数 在代码开始的地方按 P
如上一步中所说的,我们先对数据按C键将数据转化为了代码,这时候还需要在代码开始的地方按p键,让IDA在将一段代码上创建成一个函数。
如下,可以注意到左边的地址是红色,这时候我们在0x4025A0地址下按p就在这一段汇编创建函数且左边的红色地址消失。
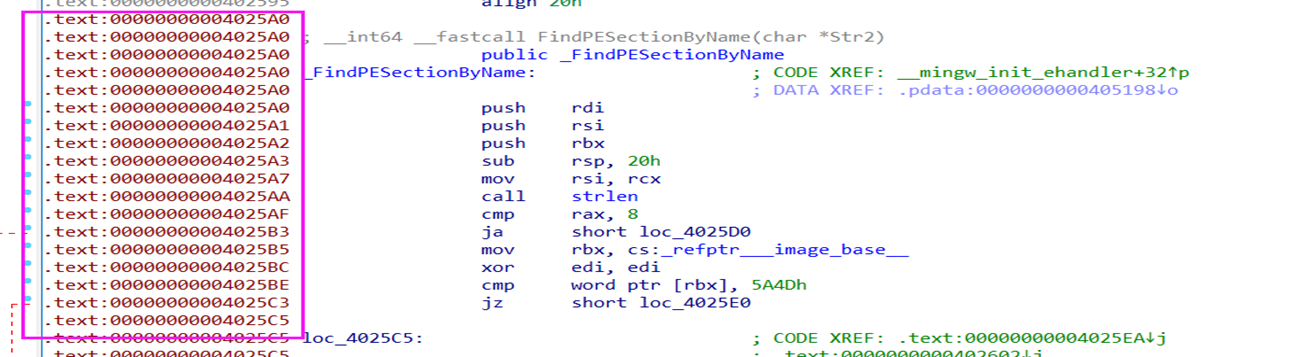
取消定义 在需要取消定义的地方按 U
通过在指定的数据或者代码下按U键我们可以取消IDA对该数据的定义,如代码,数组等。
如下,我们在aDS按u键后,得到了下面第二张图的结果。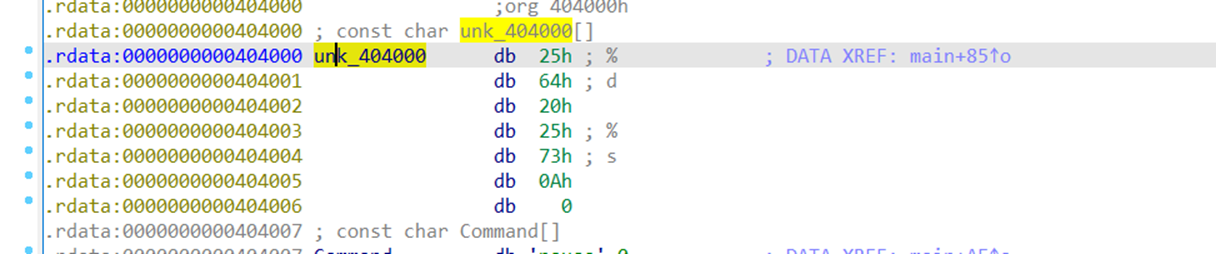
定义数组 在需要定义为数组的数据开始的地方按 *
分析一个程序时,我们有时候在硬编码的数据中看见一段连续的数据且我们确定它为数组,但IDA并没有将其解析为数组,这时候我们就可以在这段数据开始的地方按下*,弹出如下所示的框:
选好满足我们要求的选项后,按ok即可。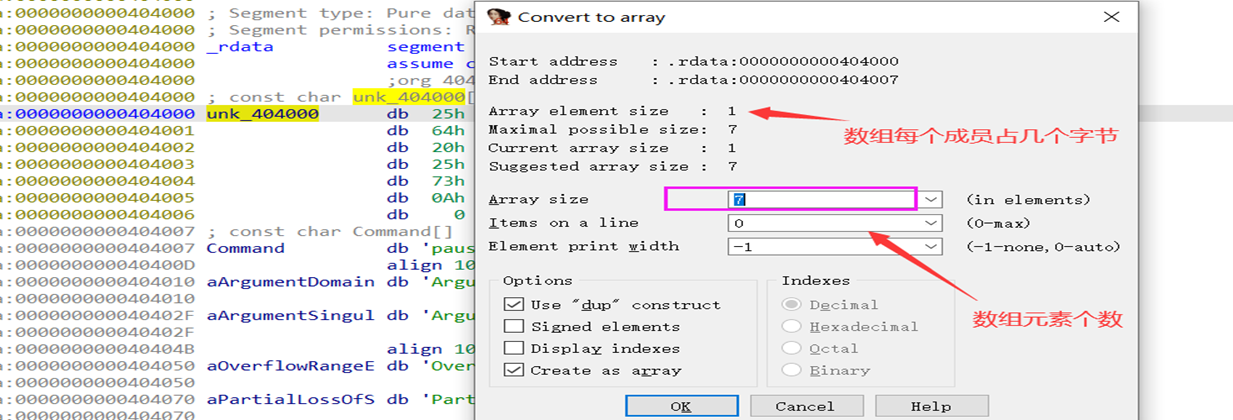
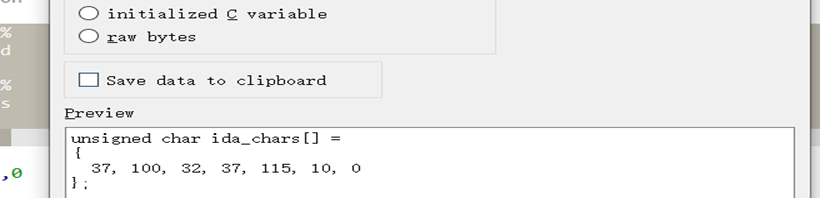
提取数据 选中要提取数据后按shift+e
在我们需要得到程序中的一段数据时,我们可以先选中这段数据然后按shift+e
如下,我们先选中数据,接着按shift+e后得到下面的第二组图:
标签的使用 加标记:alt+m 跳转到标记:ctrl+m
使用标签功能我们可以在程序代码的任何位置快速跳到我们做了标签的地方,这对于快速跳到关键代码的位置是很实用的。
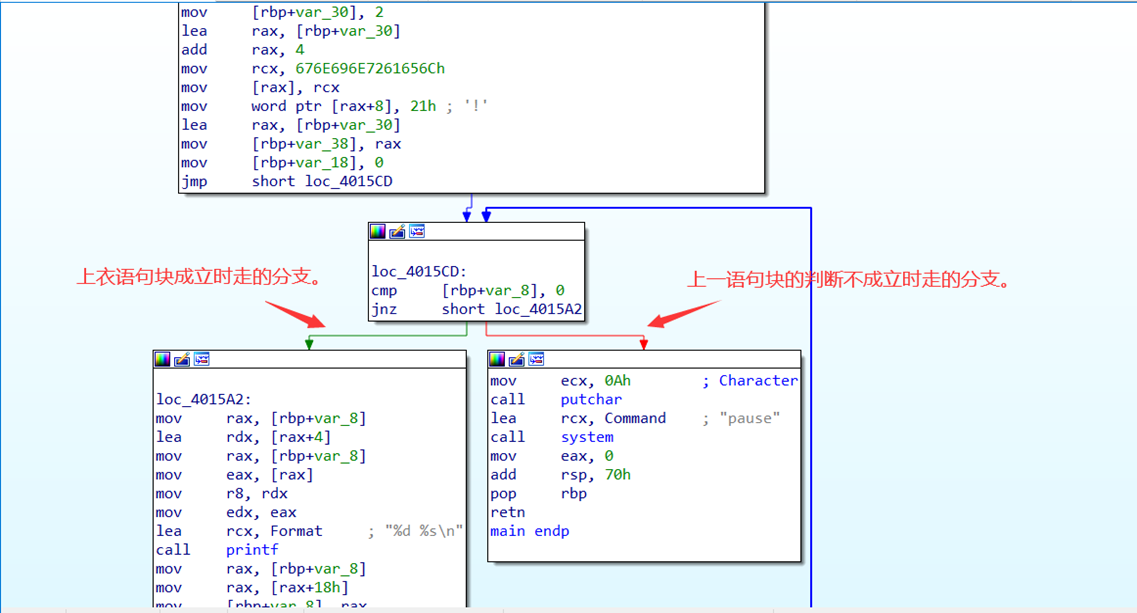
如在下图中,我们知道了0x4015A2地址处是printf的功能,那么我们可以在这个地址下按alt+m,对这个地址加上printf的标记。那么当我们此时在程序任何位置,按crtl+m,选中printf标记就可以快速跳回到这里了。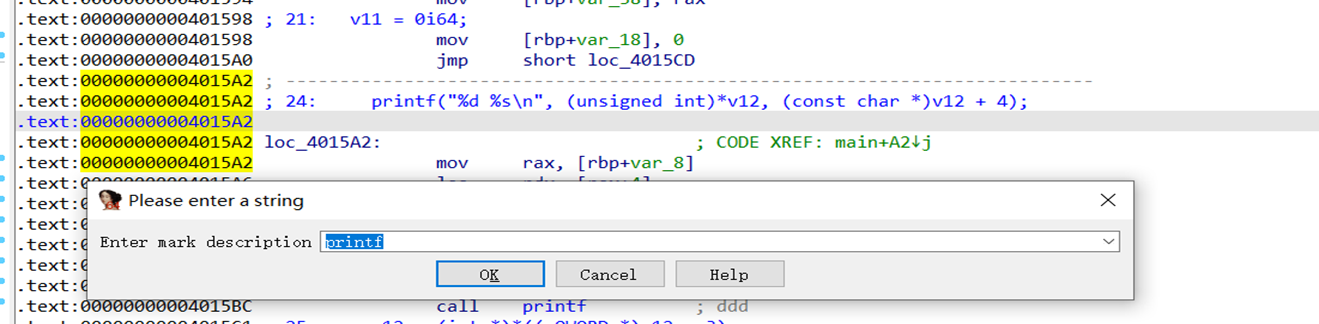
快捷键
- F5 : 反汇编当前函数
- ; :为当前指令添加全文交叉引用的注释
- N :定义或修改名称,通常用来标注函数名
- G :跳转到任意地址
- Esc :返回到跳转前的位置
- H :十六进制显示数据
- y :改变数据类型
- X :查看按上层调用
- Space :图形视图和文本视图切换
- Shift+f12:字符串窗口列表
- 二进制搜索:alt+b
- 文本搜索:alt+t
- 快照:shift+ctrl+w
- tab:反编译与流程图切换
- alt+a:字符串操作
- 流程按/:流程图加上伪代码
IDA插件的安装
若我们有想要安装的插件,直接到将其放到IDA安装目录中的plugins文件夹下即可。
IDA的高级使用
ida中字符串搜索的技巧
ida中有两种搜索:文本搜索(alt+t),二进制搜索(alt+b)
而文本搜索是很局限的,他只是对在shift+f12中ida已经列出来的字符串中搜索,对于很多很多中文字符串,宽字符它都是搜索不出来的。
所以一般着重使用二进制搜索:
1.对要搜索的十六进制字符串以空格分隔为两位十六进制值组成的列表。
2.要搜索内嵌的字符串数据,必须将要搜索的字符串用双引号括起来。
3.在搜索十六进制字节序列时,最好选中Match_case选项,不然,假如要搜索的序列为:E9 41 C3,而E9 61 C3也出现在了搜索结果中。这是因为,0x41对应于字符A,而0x61则对应于字符a,所以IDA认为这两个字符串相互匹配。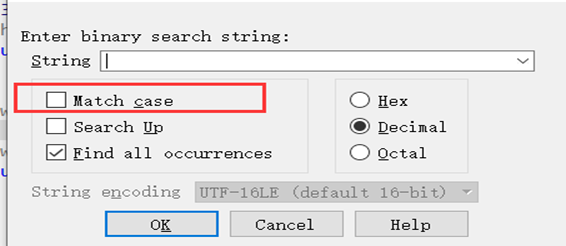
得到一个函数与调用它的函数之间关系图
在一个函数的图形化界面右键选择Xref graph to..
如下得到了main函数与调用main函数之间的关系图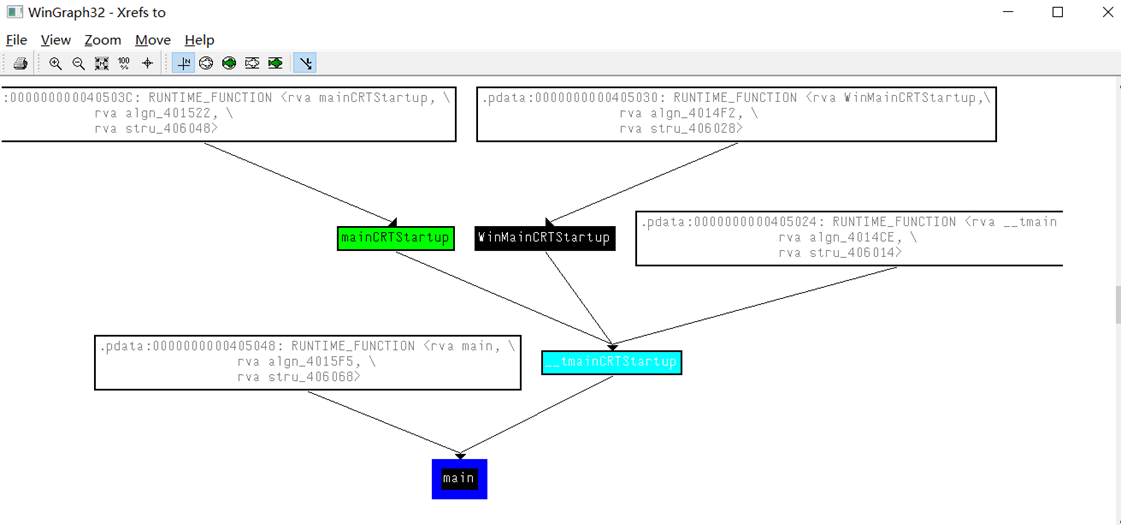
得到一个函数与它调用的函数之间关系图
在一个函数的图形化界面右键选择Xref graph from..
如下得到了main函数与main调用函数之间的关系图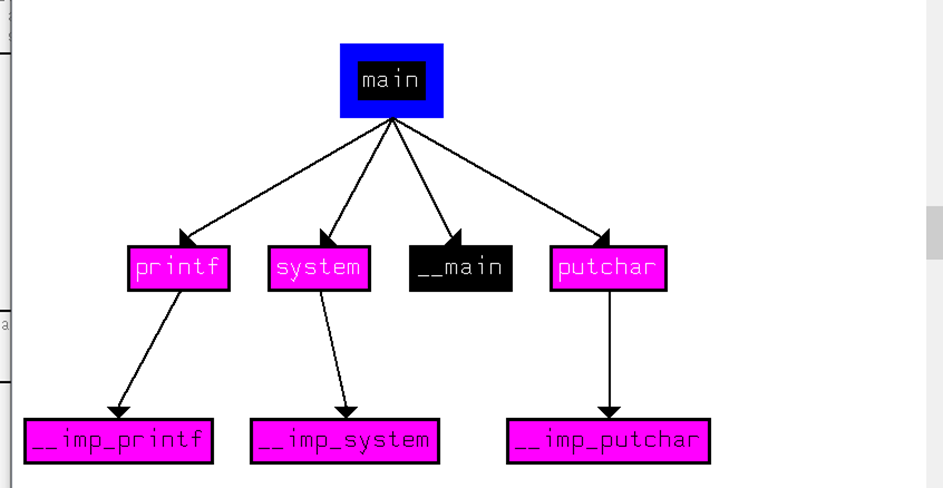
修改字符串窗口的设置以得到尽可能多的字符串
有时候我们可能发现程序中长度为4的关键字符串在字符串窗口找不到,其实这是ida中设置的原因,默认字符串窗口能显示的字符串长度为5。
在字符串窗口右键后点击Setup,然后将最小字符串长度改为4就好。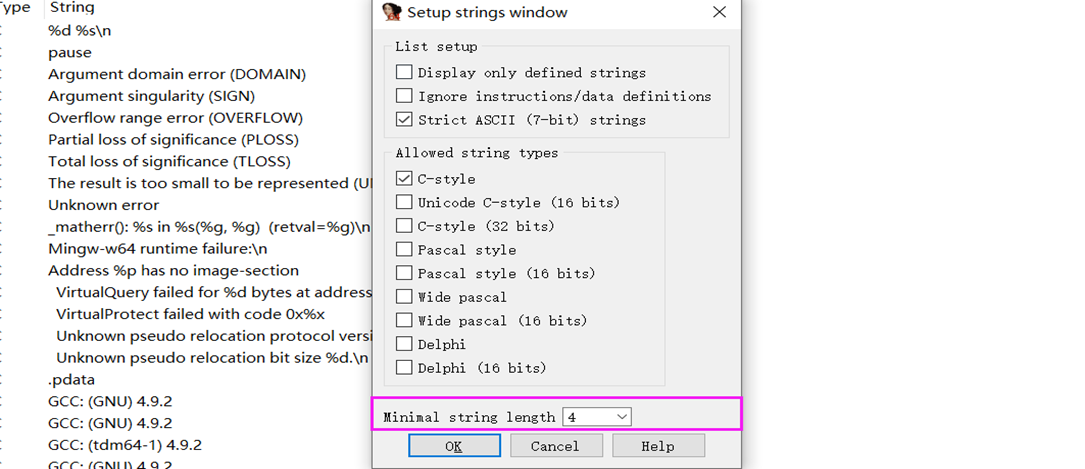
对比源代码中结构的定义与ida对结构体反编译结果来熟悉看伪代码
源代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct _Link
{
int data;
char a[20];
struct _Link *next;
} Link, *pLink;
int main(void)
{
pLink head;
Link link, link1;
head = &link;
link.data = 1;
strcpy(link.a, "IDA工具的使用");
link1.data = 2;
strcpy(link1.a, "learning!");
link.next = &link1;
link1.next = NULL;
while(head)
{
printf("%d %s\n", head->data, head->a);
head = head->next;
}
putchar(10);
system("pause");
return 0;
}
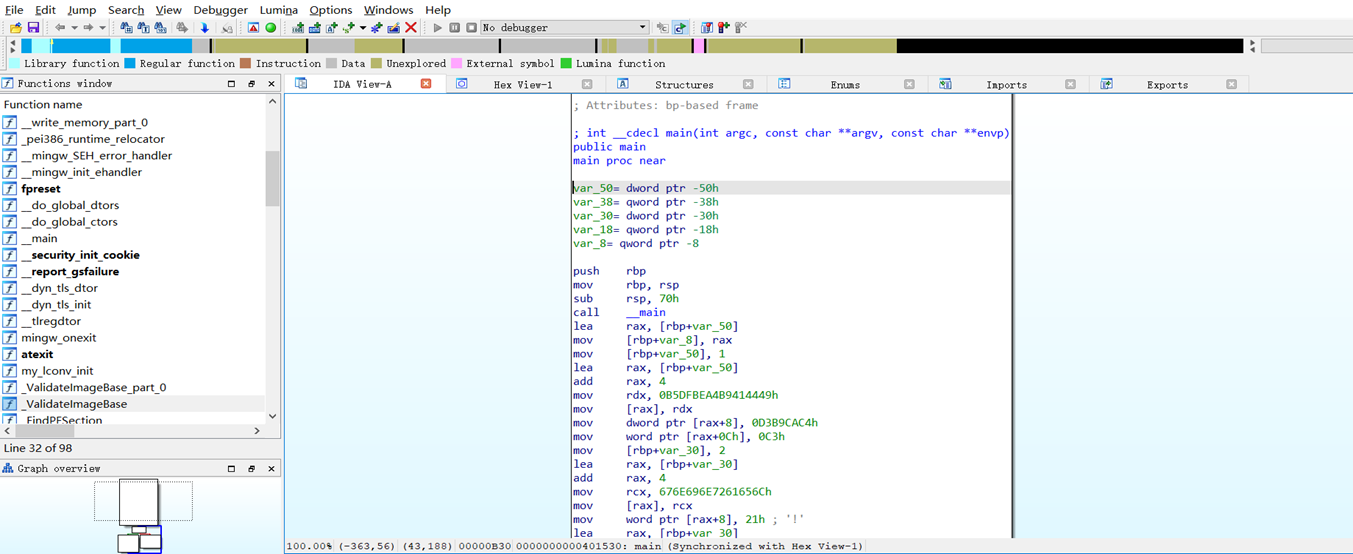
Ida反编译结果:
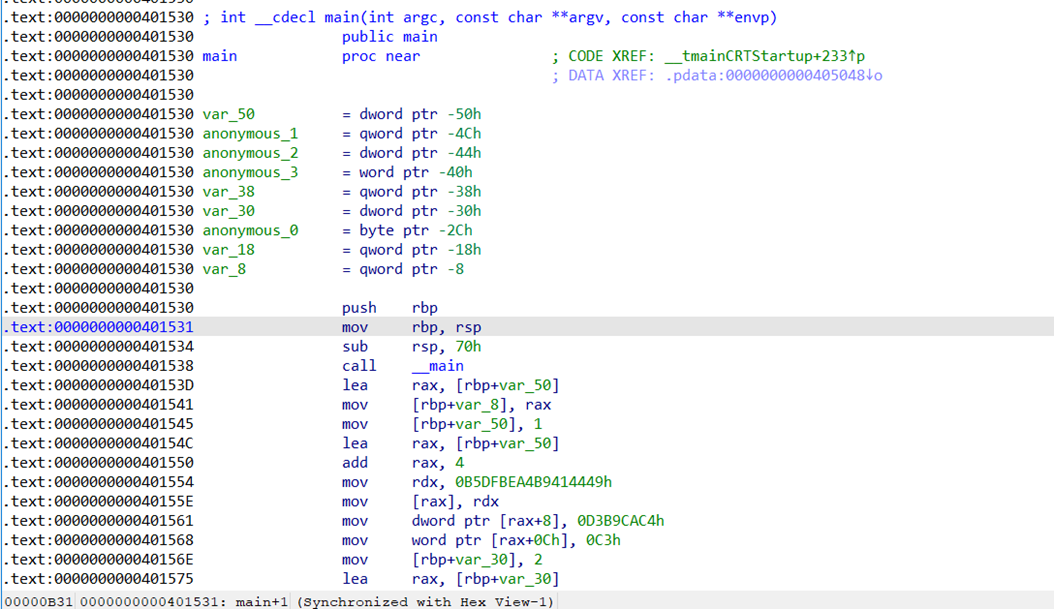
int __cdecl main(int argc, const char **argv, const char **envp)
{
Link link; // [rsp+20h] [rbp-50h] BYREF
Link link1; // [rsp+40h] [rbp-30h] BYREF
pLink head; // [rsp+68h] [rbp-8h]
_main();
head = &link;
link.data = 1;
*(_QWORD *)link.a = 0xB5DFBEA4B9414449ui64;
*(_DWORD *)&link.a[8] = -742798652;
*(_WORD *)&link.a[12] = 195;
link1.data = 2;
strcpy(link1.a, "learning!");
link.next = &link1;
link1.next = 0i64;
while ( head )
{
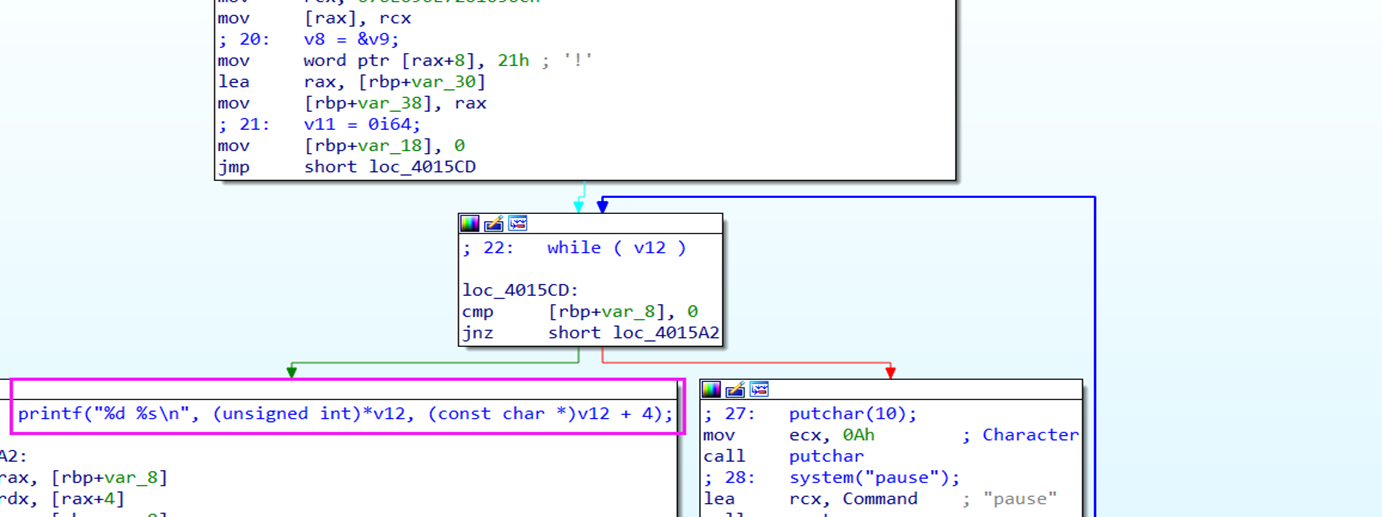
printf("%d %s\n", (unsigned int)head->data, head->a);
head = head->next;
}
putchar(10);
system("pause");
return 0;
}
对比源代码中结构的定义与ida对结构体反编译结果来熟悉看伪代码
从上面的结果我们可以看出,源代码中定义的结构体它的实质就是分配一块内存,然后这块内存组织了其中变量。但是ida反编译时并不能将其还原出来,它只能得到它的实质结果,那就是一段连续的空间上每个变量分别定义出来。我们在分析出结构体后,插入创建分析出的结构体后再应用就能在IDA中还原出结构体了。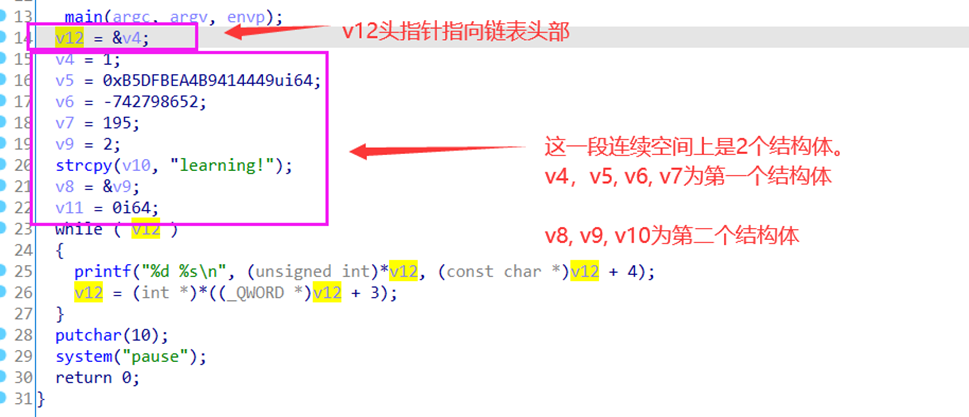
IDA中python脚本的编写 载入脚本执行:alt+f7 打开执行脚本窗口:shift+f2
在下面的窗口中写python代码可以很好的和IDA交互。要用的api查官方文档:https://hex-rays.com/wp-content/static/products/ida/support/idapython_docs/
解决ida反编译遇到:Decompilation failure:xxxx:too big function
这是因为ida默认反编译函数的大小只有64K,所以这里会反编译会失败。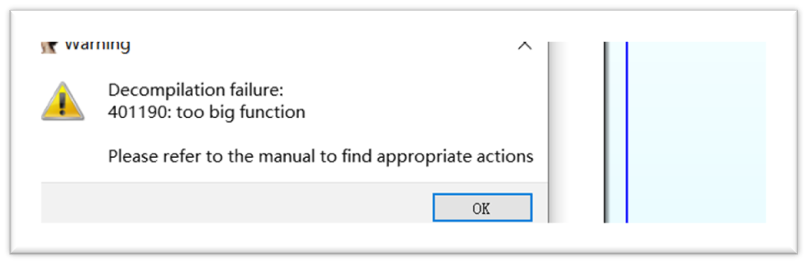
这个问题可以通过修改反编译插件的配置文件\cfg\hexrays.cfg中MAX_FUNCSIZE,改为1024就好了
动调调试-windows
按下图所示选择好指定好选项,程序中下好断点,直接F9程序就调试起来了。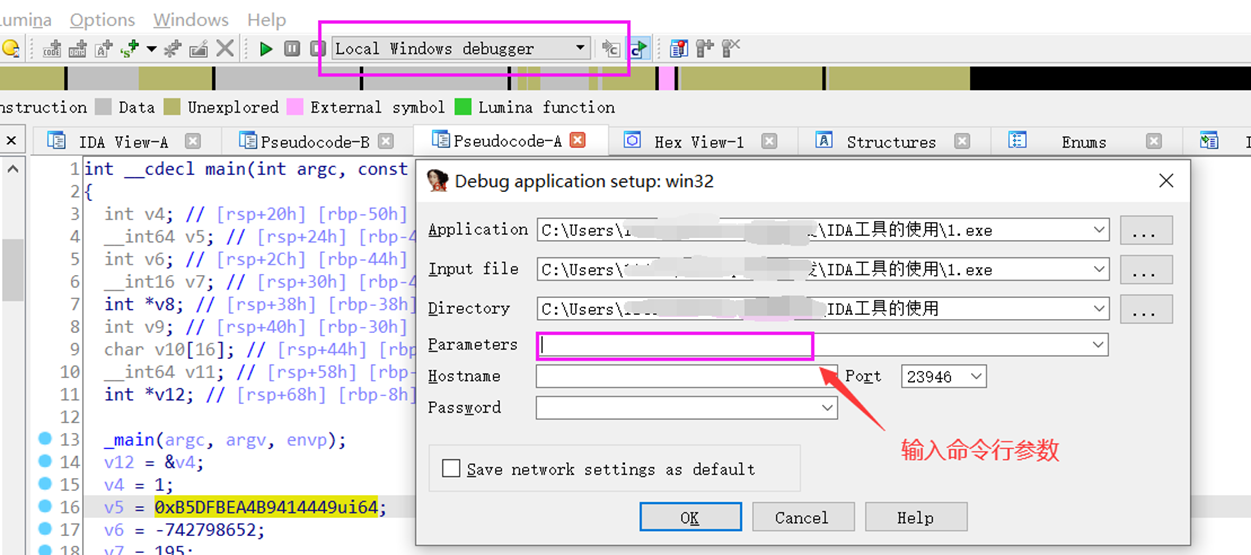
动调调试-linux-x86
首先找到IDA的dbgsrv文件夹
进入dbgsrv文件夹
其中linux_server是我们调试32elf文件所要使用的服务程序,linux_server64是调试64elf所要使用的服务程序。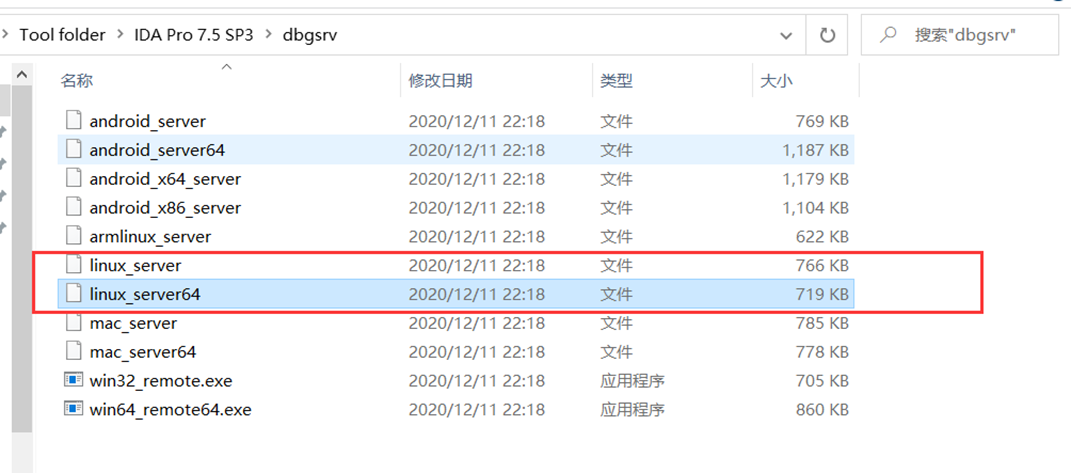
将上面提到的2个服务程序复制到linux虚拟机和所要调试的文件放在同一个文件夹下。这里为了以后方便也可以放入/usr/bin/下,以后直接通过命令(linux_server或linux_server64)就启动了。
使用chmod 777 linux_server linux_server64,赋予这两个文件有执行的权限。
然后根据我们所要调试程序的位数启动对应版本的服务程序。
使用ifconfig命令查看当前虚拟机的ip地址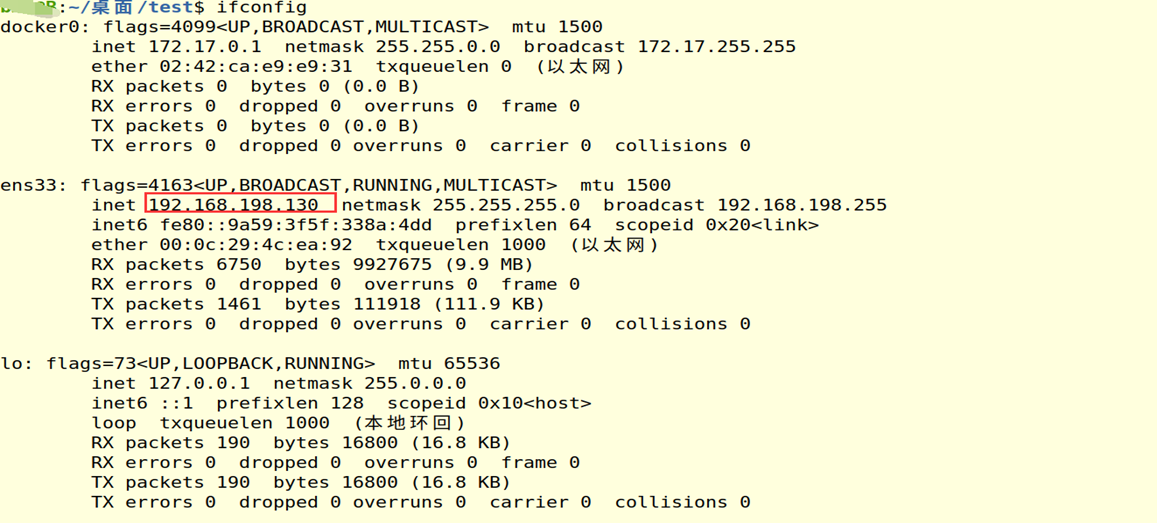
配置ida中调试选项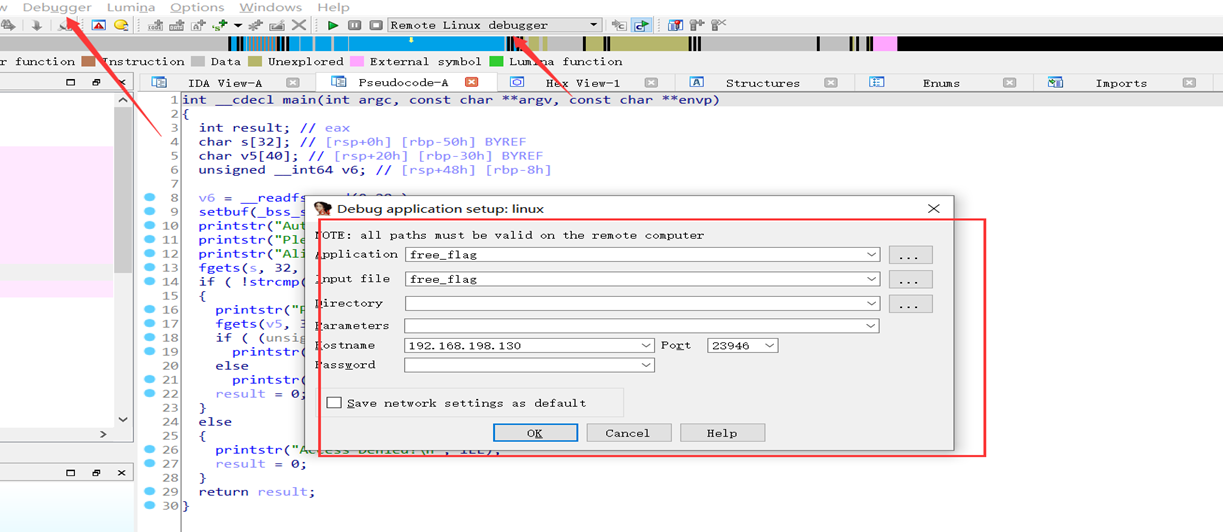
最后注意本机与目的linux环境能相互ping通,下好断点,直接F9启动程序即开始调试。
IDA中制作sig文件
IDA中的sig文件是什么?
它是满足IDA中FLIRT(库文件快速识别与鉴定技术)而使用的一种签名文件。它使用自定义的格式,记录了一些库函数的特征序列值。在我们找到合适的库文件并以此制作相应的签名文件后将其应用IDA中,它将通过特征值自动去匹配程序中的函数,并对匹配上的函数自动重命名(要注意的是:就算匹配上它也只会对IDA默认命名函数的函数重命名,换句话说就是如果之前我们对该函数已经进行了重命名,那么之后就算签名文件匹配上这个函数也不会对其进行重命名)。这能很好的解决静态编译且去除符号程序因本身函数与库函数混杂在一起增大了我们分析程序难度的问题,帮助减少工作能,更快的去分析程序本身的函数。
IDA中自带的签名文件
在IDA安装目录中的sig文件夹下我们能找到IDA中本身自带的签名文件。不同文件夹表示不同架构平台要使用的签名文件。这里我们在自己添加签名文件时也一定要注意好其架构。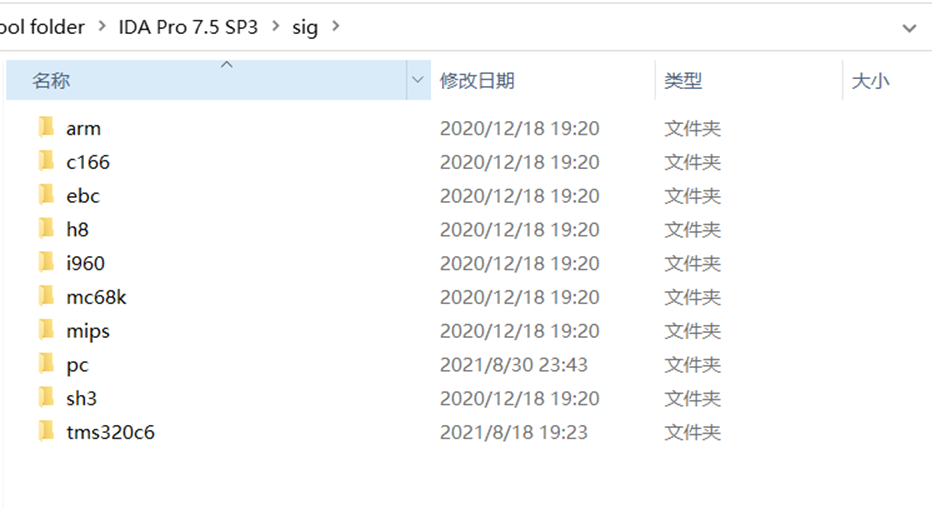
在IDA自带的签名文件中只有一小部分类unix下的签名文件,这是因为在类unix下使用编译器的是开源的gcc,不同的linux发行版本的libc.a也都不尽相同且更新很快,IDA也就不可能把所有版本的libc.a都制作一份签名文件保存下来。所以在我们分析静态链接且去除了符号表的elf文件时,可以发现很多库函数都没有识别出来,这在程序很大时无疑增加了它的分析难度和我们所花费的精力。
下面也是以一个静态链接且去除了符号的elf文件来一步一步找到它的库并制作相应的sig文件进而恢复它的符号。
查看分析的elf文件未引用sig文件时的main函数
如下所示,所有函数都是没有符号的。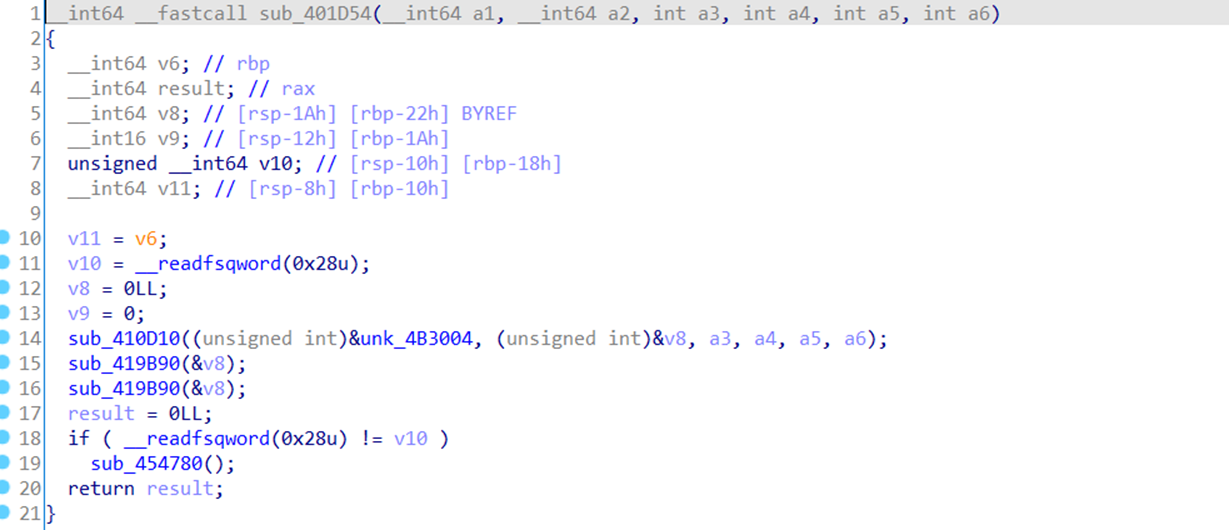
查看该elf文件的字符串信息尽可能找到该elf文件的编译平台
strings -a 1 | grep ‘ubun’

找到目标环境下的libc.a文件
whereis libc.a

下载IDA官方提供的FLAIR工具集,我们选择使用linux下平台的文件
将linux文件夹拖入我们的linux环境中
使用linux文件下的pelf将libc.a转化为libc.pat
./linux/pelf libc.a libc.pat
如果正常的话不会有提示信息,在当前文件下生成libc.pat文件。
但也常出现下面这个错误:
看意思是不能识别重定位类型,那我们在上面的命令下加上如下选项即可:
./linux/pelf -r42:0:0 libc.a libc.pat
42是重定位类型,根据提示的错误来。
接着使用sigmake将libc.pat文件制作成libc.sig文件
./linux/sigmake -n“my_sig” libc.pat libc.sig -n后是添加的注释信息
正常的话也是直接就生成相应的sig文件了。但也常出现下面的错误:
意思是有22个函数它们同一个特征值不止对应一个函数,如果制作成了sig文件在匹配成功时也不知道到底应用那个函数名字。

它会在当前目录下生成一个.exc文件,它是可编辑的,我们将该.exc文件的前几行注释删除,在我们要选择特征值对应的函数名称最前面加一个+号即可,如果不管就什么也不加。如下图,我选择了第一个该特征值的第一个函数。
修改完.exc文件后,再次重复之前生成sig文件的命令就好了。
./linux/sigmake -n“my_sig” libc.pat libc.sig
应用生成的sig文件到IDA中
将生成的签名文件复制到IDA中的sig目录下。
回到IDA中之前分析的该elf文件,shift+f5打开应用库的窗口,然后右键把我们新复制到的sig目录下的sig文件添加进来。如下图,添加后,成功匹配了程序中的735个函数。而上面之前的libc却匹配了0个函数,这也正说明了版本变化带来的差异之大。
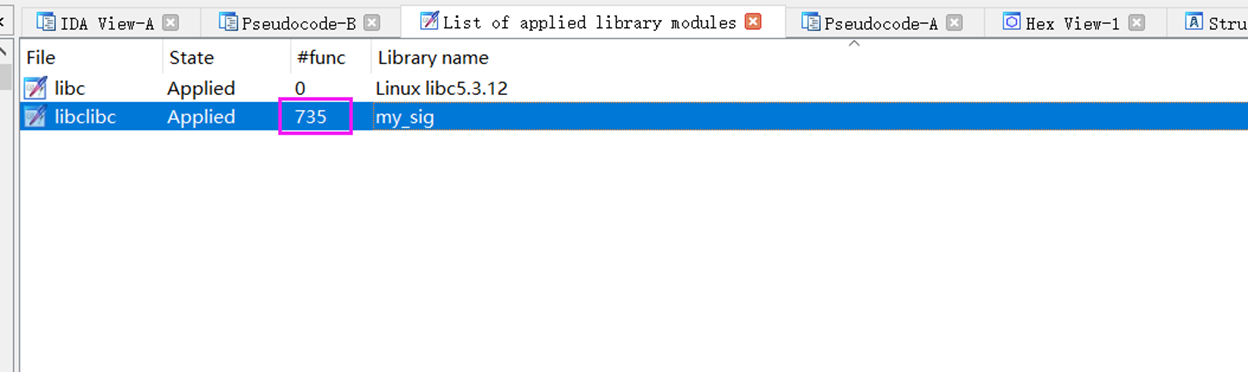
查看应用新sig文件后的main函数
如下图,scanf和puts相关函数都识别出来了。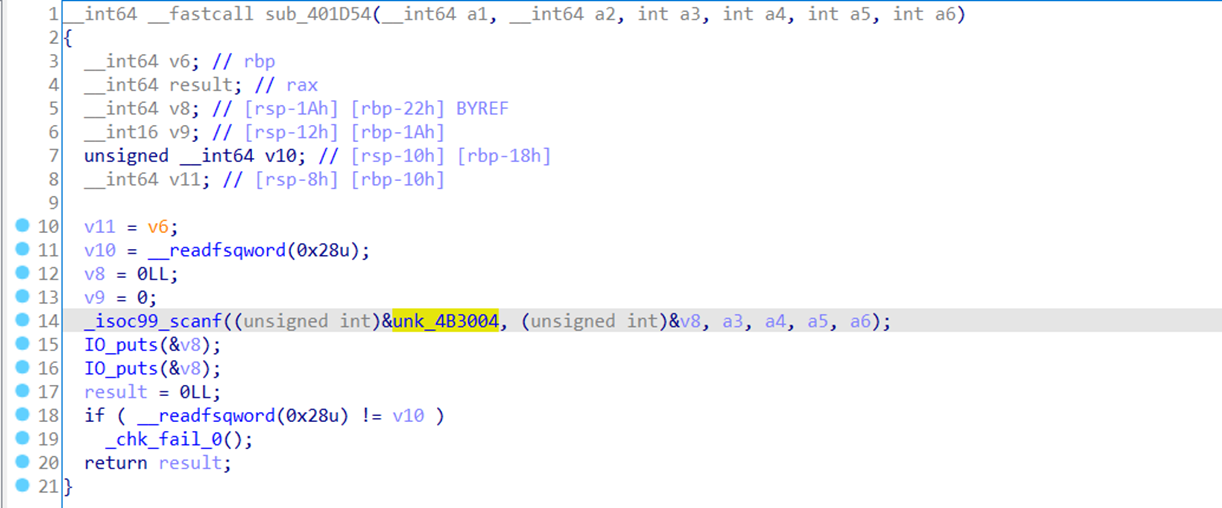
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 jaytp@qq.com

