当前主流的模型聚焦与道路面的提取
TOPO是比较真实路网和计算路网上起点和终点的距离差异
SP是比较起点和终点之间最短路径的相似度
Junction主要是衡量路口间的误差程度
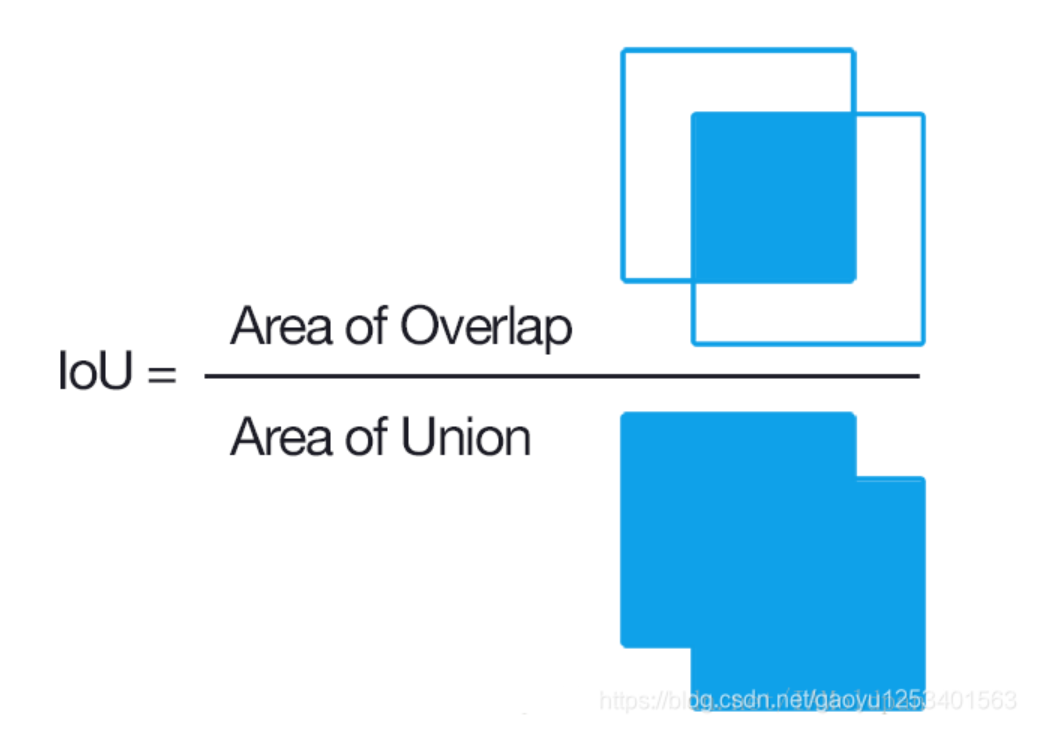
IoU是一种测量在特定数据集中检测相应物体准确度的一个标准
IoU是两个区域重叠的部分除以两个区域的集合部分得出的结果,通过设定的阈值,与这个IoU计算结果比较。
HSV色彩空间:
基于色调、饱和度、亮度
色调H指光颜色,区间为[0,180]
饱和度S指色彩深浅,区间为[0,255],当饱和度为0时,图像变为灰色图像
亮度V指光的明暗,当饱和度相同时,亮度值越大,图像越亮,当亮度为0时,图像为纯黑色
灰度图像RGB三通道值相同就能得到
alpha通道为图像透明度通道
边缘特征提取方法
一阶微分算子:
利用图像灰度函数的梯度来检测边缘(利用梯度来检测图像中灰度值变化剧烈的区域,这些算子通过计算像素点在水平和垂直方向上的梯度值来检测边缘,当梯度值超过某个阈值时,认为该点是边缘点);
二阶微分算子:
相比于一阶导数,二阶导数可以提供更多的边缘信息,例如边缘的方向和边缘的强度
Canny边缘检测:
- 利用高斯滤波器,来平滑图像,去除噪音
- 计算图像中每个像素点的梯度强度和方向 sobel算子,c塔为方向
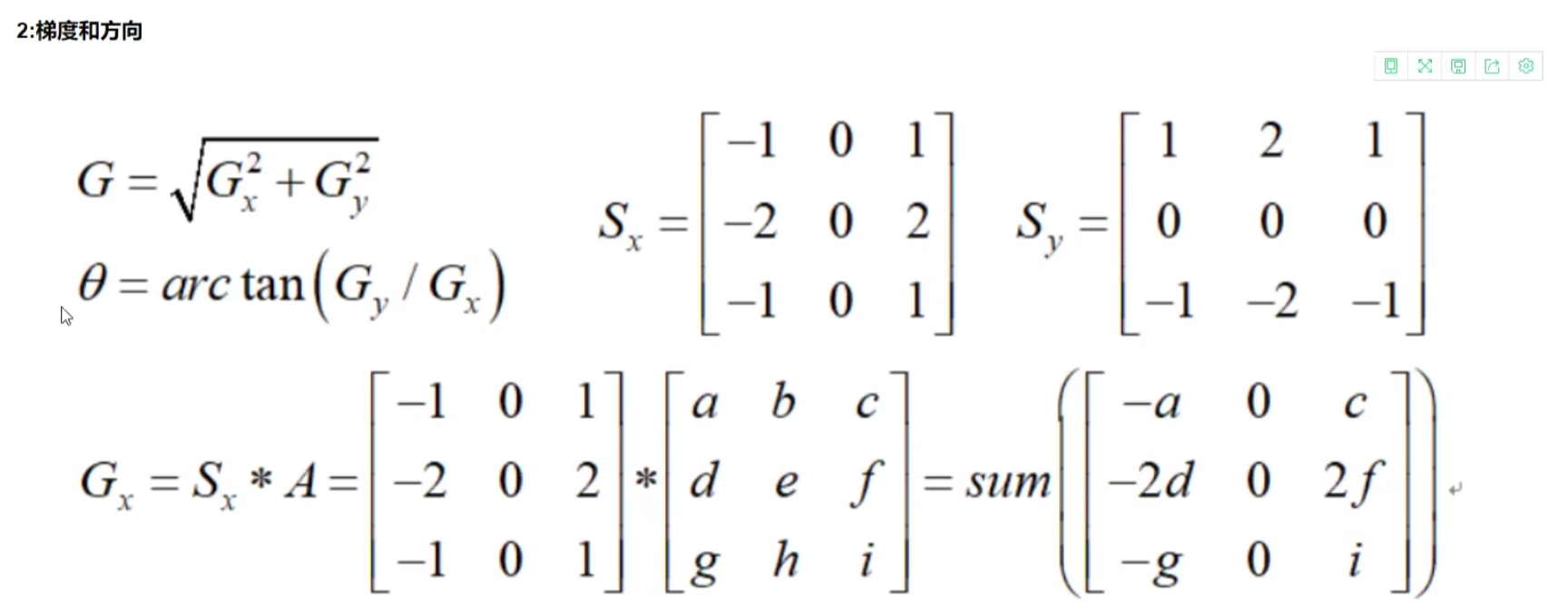
- 应用非极大值抑制,以消除边缘检测带来的杂散响应(保留大梯度,显示明显边缘)

- 应用双阈值检测潜在和真实的边缘 (过滤边界,只保留最真实的一部分)

- 通过抑制孤立的弱边缘最终完成检测
边界存在梯度,所以梯度自然和边界垂直
利用多阶段滤波和梯度幅值来检测边缘,并使用非极大值抑制和双阈值检测来确定最终的边缘点;
非极大值抑制(NMS技术):去除检测出来的冗余框,保留最优框(对比每个框的重叠面积)
双阈值检测:
图像阈值化:根据图像内像素点强度的分布规律设置一个阈值,根据像素点强度是否低于/高于阈值进行处理。用于突出边缘或纹理
Ostu方法遍历所有可能的阈值,从中找到合适的阈值
二值化处理得到物体轮廓
原始图像->灰度图像->二值化图像->反二值化 物体边缘信息变得鲜明
感兴趣区域ROI(掩膜): 从图像中选择一个图像区域,以便进一步处理img[R1:R2,L1:L2]
np.ones((101,101,3))创建一个101×101的三通道图像
图像融合是在图像加法基础上增加了权重不同的系数和亮度调节:cv.addWeighted(img1,weight1,img2.weight2,light)
查找目标模板在图象中处在什么位置叫模板匹配
cv2.matchTemplate的输出是[W-w+1,H-h+1]的32位浮点型数组
单目标匹配只返回匹配度最高的结果
多目标匹配将原始图像中所有与模板相似的图像都找出来,使用相关匹配或相关系数匹配可以实现
在一张图片中同时查找多个模板叫多模板匹配?
平滑处理(图像模糊处理),去除图像内噪声、降低细节层次信息,工具 滤波器
均值滤波器、:滤波核内像素平均值

中值滤波器 将滤波核的像素大小排序然后取中间值
高斯滤波器(使用最广泛) 分配像素权重,远离核心权重小,靠近核心权重大
双边滤波器 平滑处理中有效保护图像边界信息,自动判断滤波核处于平坦还是边缘
- 平坦 高斯滤波
- 边缘 加大权重,尽可能让像素保持不变
腐蚀与膨胀
为了清除和强化图像中的细节
- 图像开运算
- 图像闭运算
- 梯度运算
- 顶帽运算
- 黑帽运算
腐蚀

膨胀

开运算
先腐蚀后膨胀,用来去除外部细节,用作数量统计
闭运算
先膨胀后腐蚀,用来去除内部细节
形态学运算
梯度运算指的是图像梯度运算,直观就是像素的变化程度: 膨胀图-腐蚀图=图像轮廓图

边缘轮廓
cv2.findContours

读数据-转成灰度图-阈值二值法-轮廓检测
Canny()方法虽然能检测出图像的边缘,但是这个边缘是不连续的,该算法根据像素的梯度变化寻找图像边缘,最终绘制精细二值边缘图像
调整双阈值来控制边缘检测的精细程度,当两个阈值都较小时,检测出较多细节;反之会忽略较多细节
轮廓近似
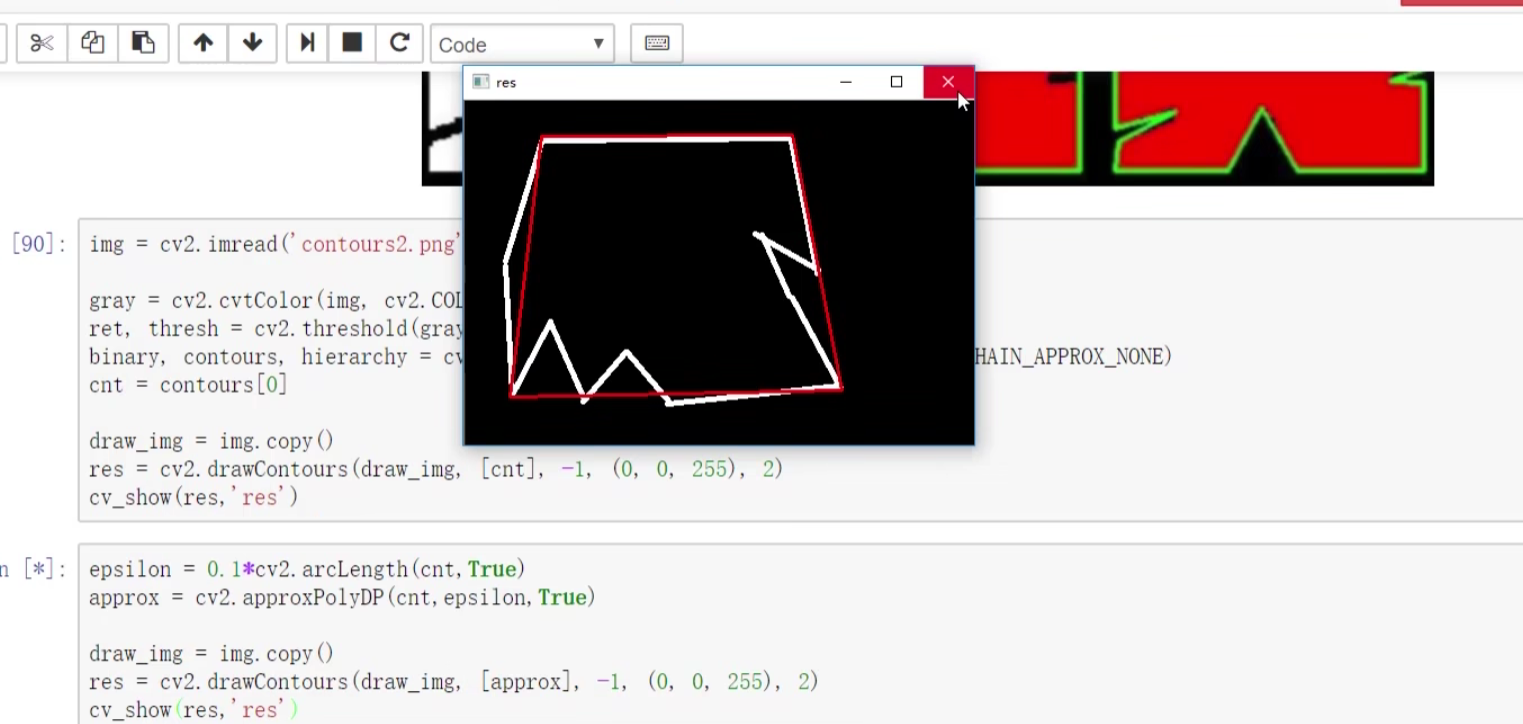
阈值设置越小,近似轮廓就越接近原始图像
轮廓拟合

凸包
如果能找到图形最外层的端点,将这些端点连接起来,就可以围出一个包围图形的最小包围框,也叫凸包,也是最接近轮廓的多边形

霍夫变换
是一种特征检测,通过算法识别图像特征,从而判断图像形状


视频处理
读取摄像头,并显示视频,用opencv的VideoCapture类相关方法,此方法还支持视频文件
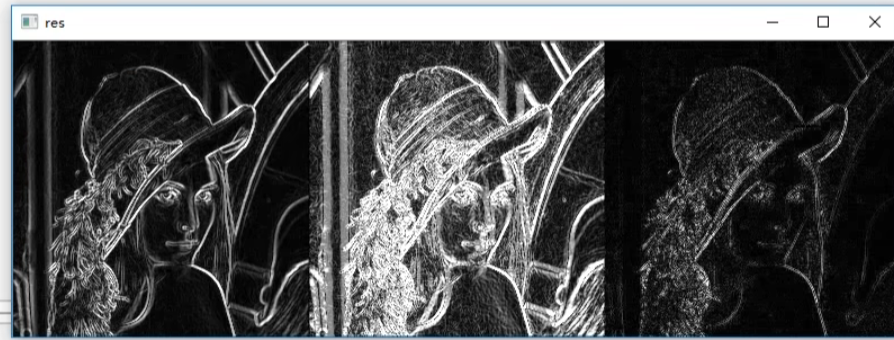
图像梯度(用于检测图像边缘信息)
Sobel算子
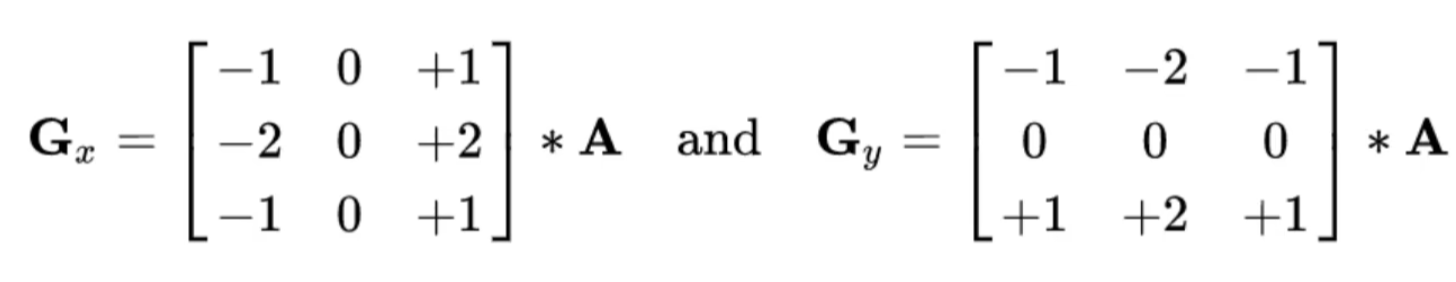
以上乘法是卷积运算,右减左,上减下;
cv2.addWeighted(sobelx,0.5,sobely,0.5,0) #水平梯度图融合垂直梯度图
Scharr算子
比较sobel,该算子核中数值较大
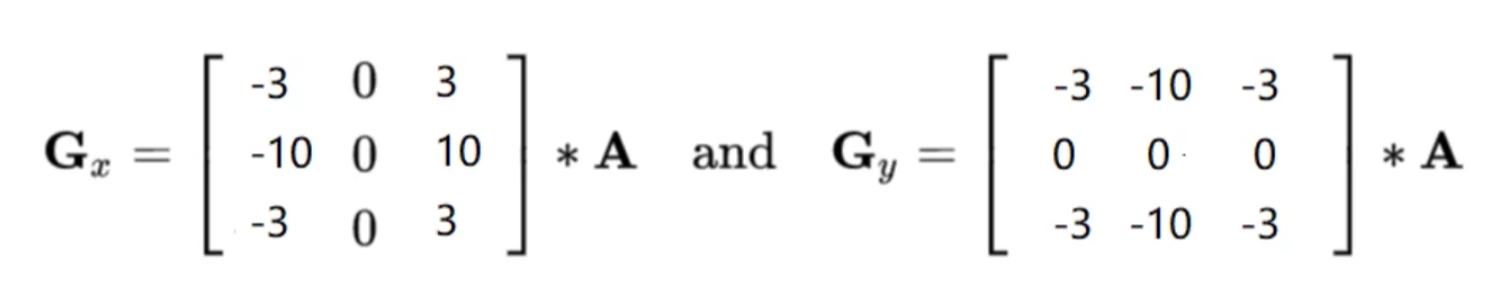
laplacian算子
该算子对梯度求二阶导,对噪声更加敏感
不用分别求x和y
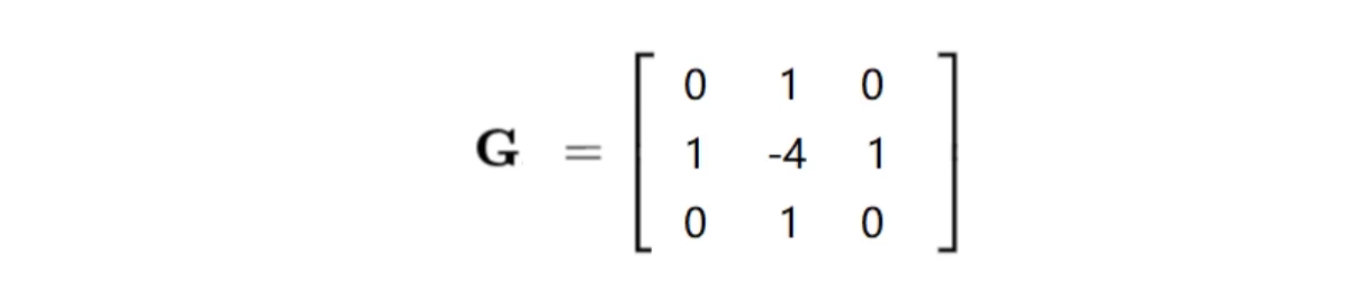
三种算子比较
图像金字塔
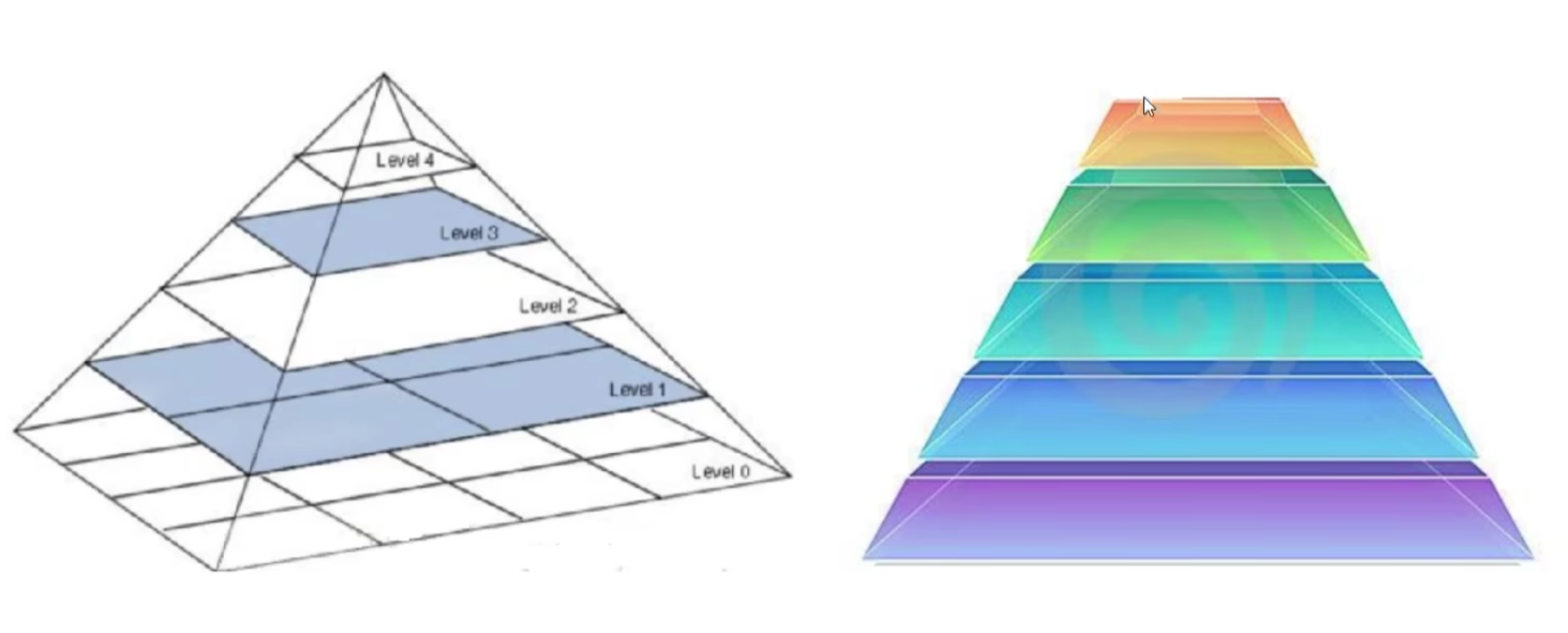
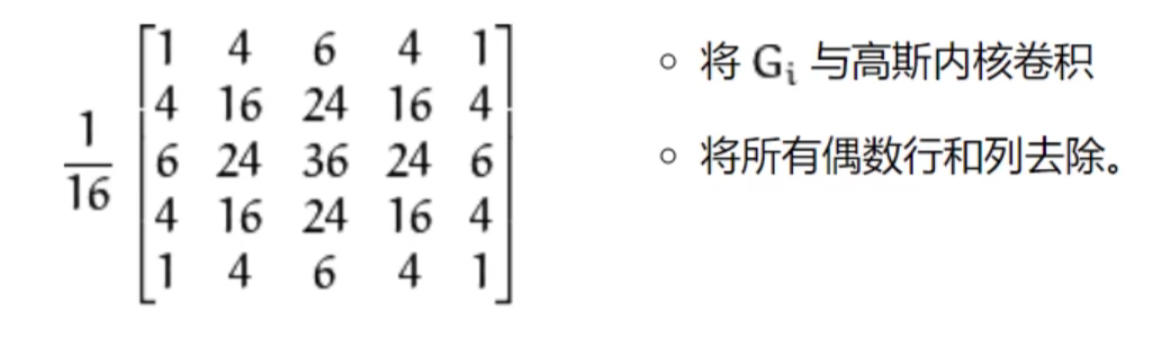
高斯金字塔(向下采样,图像缩小)
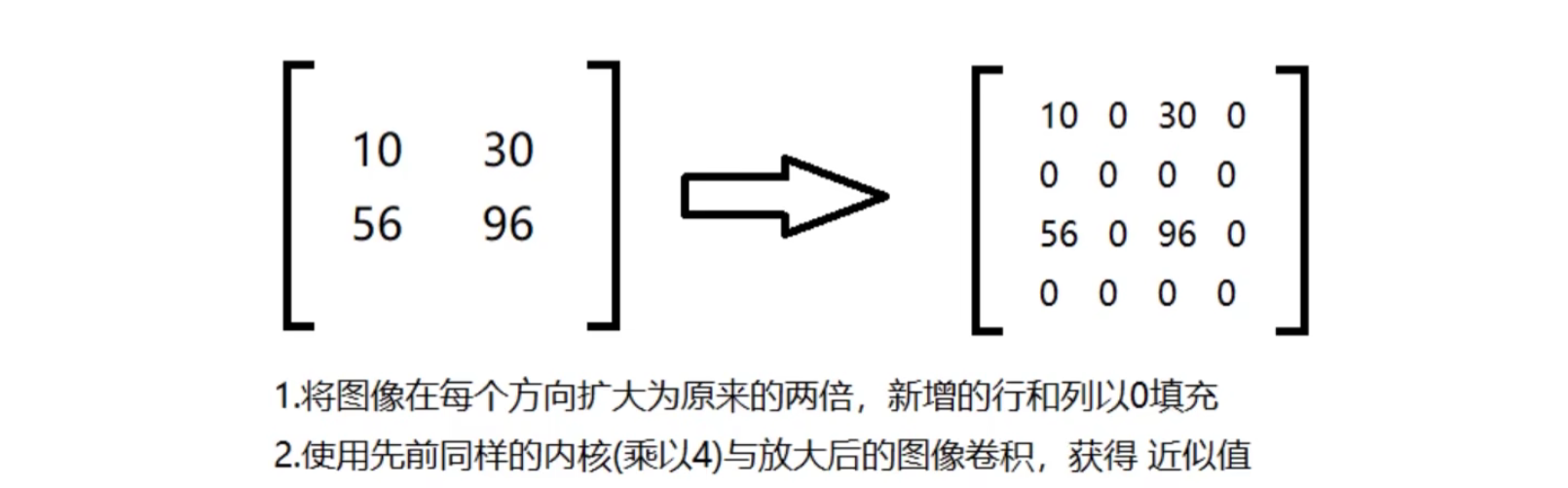
高斯金字塔(向上采样图像放大)
拉普拉斯金字塔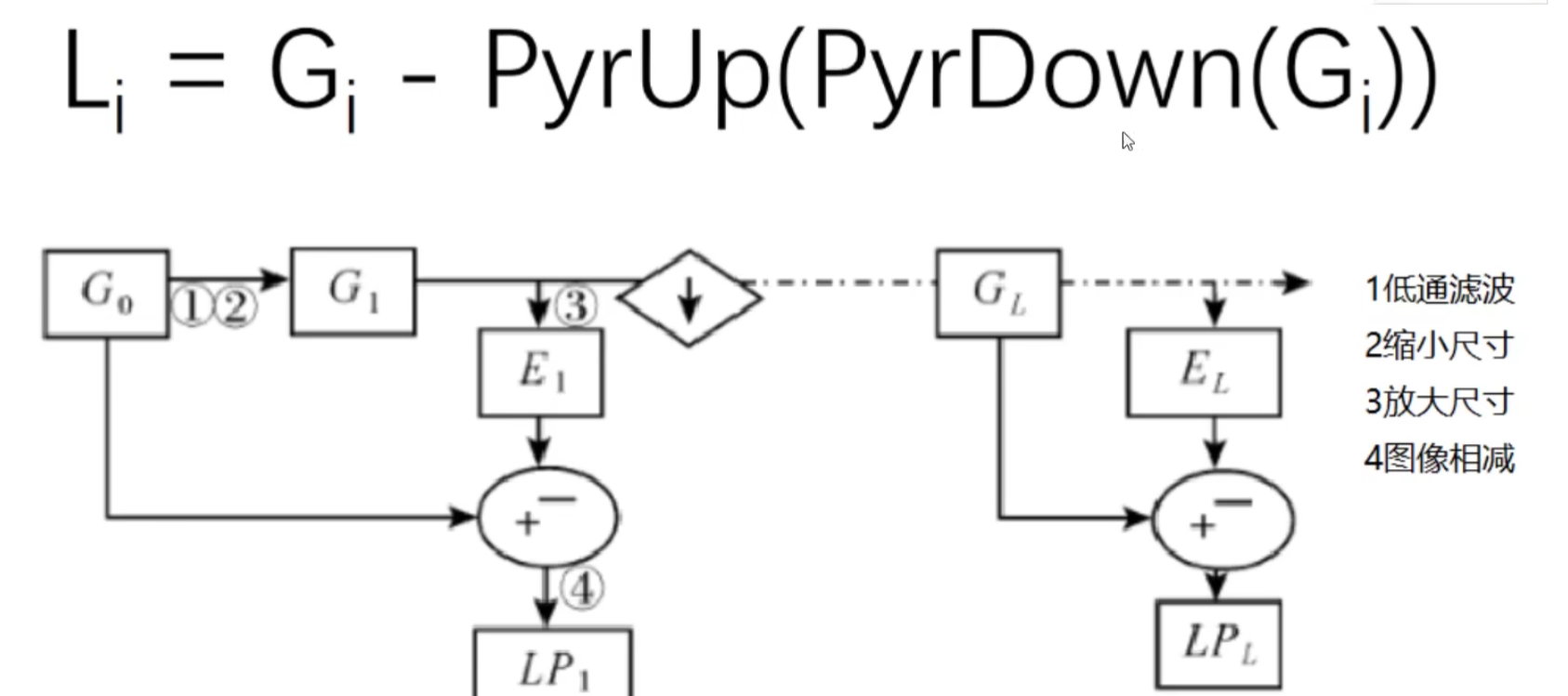
G表示输入img,G-(u_d)
1,2即为下采样操作
随后上采用和原始图像做减法,4操作
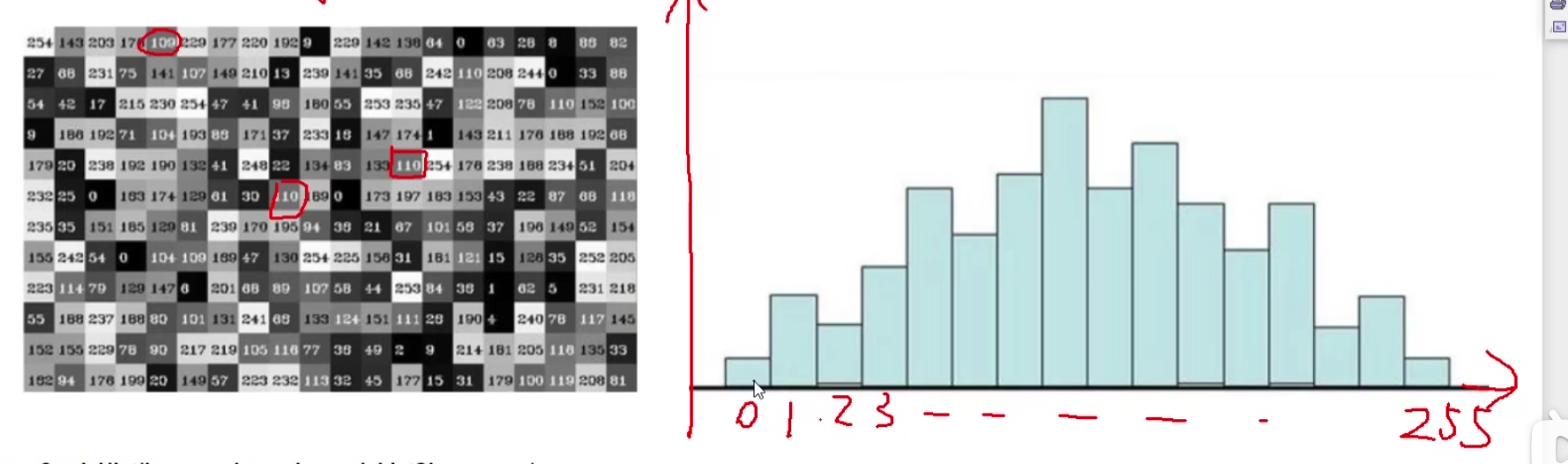
直方图
统计每个像素值在图像中出现的次数
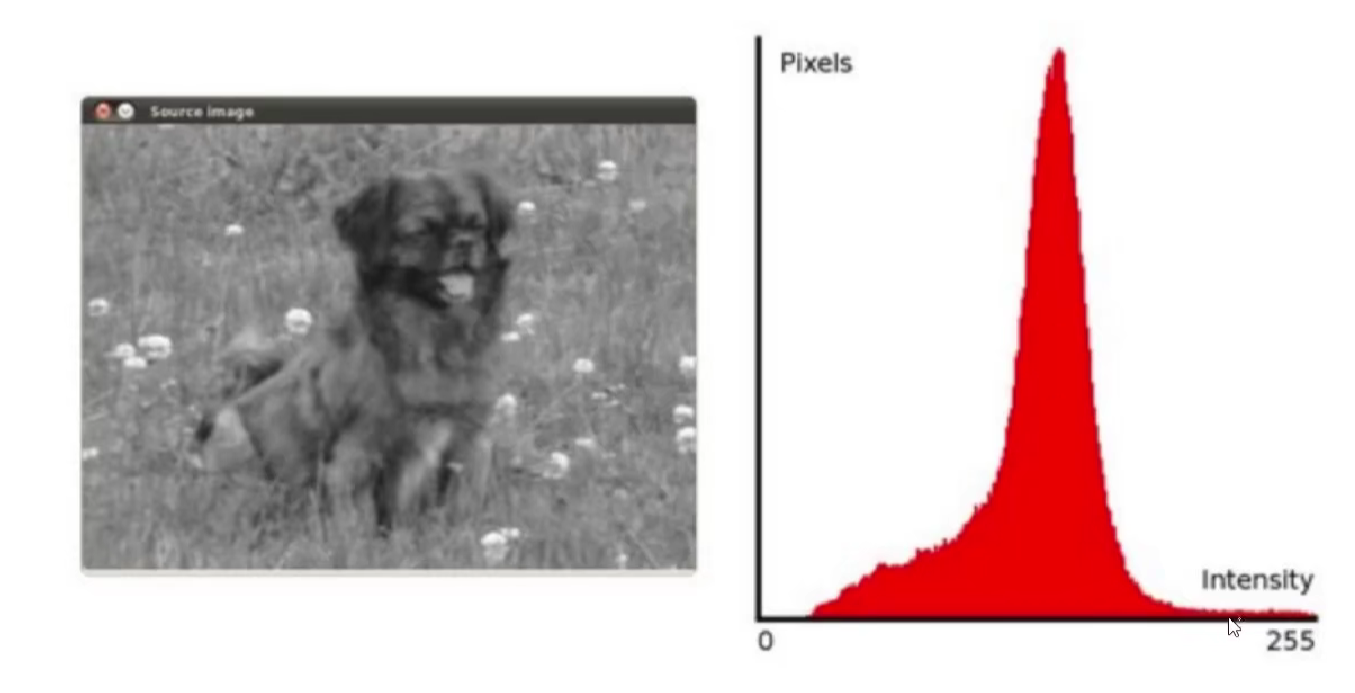
直方图均衡化
直方图中某些位置的数量特别多
 、
、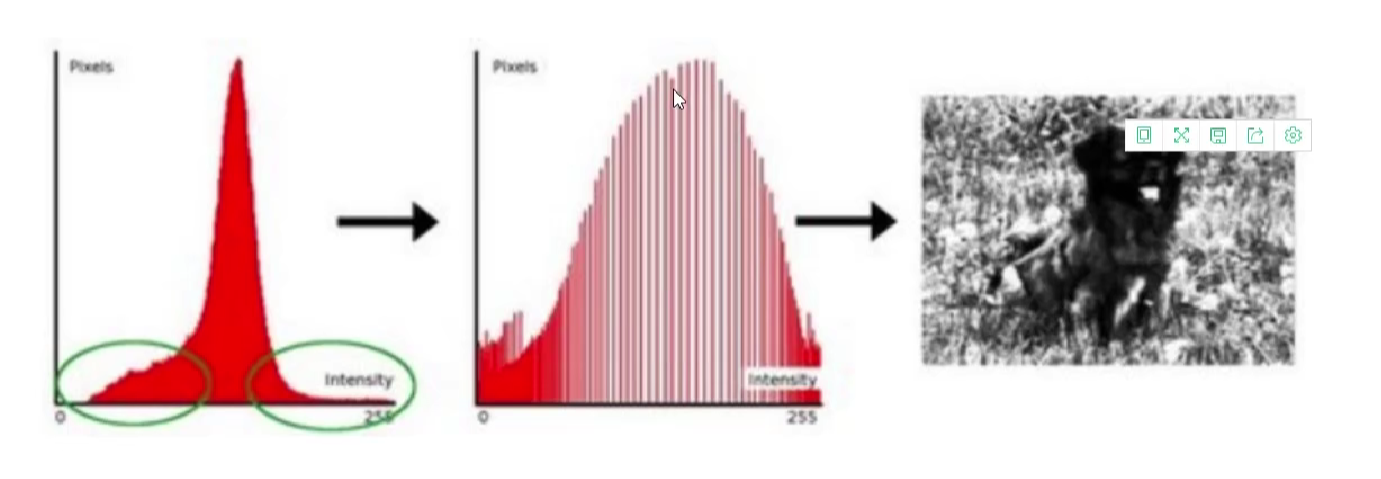
- 分灰度值数量进行统计
- 随之计算各值的概率和累计概率、
- 进行函数映射
- 映射后的像素个数取整
自适应直方图均值化

将图像切成若干块,进行分别均值化
傅里叶变换
傅里叶变换作用:
- 高频:变化剧烈的灰度分量,例如边界
- 低频:变化缓慢的灰度分量,例如一片大海
滤波:
- 低通滤波器:只保留低频,会使得图像模糊
- 高通滤波器:只保留高频,会使得图像细节增强
人所看到的世界与时间相关,随时间发生变化,用时间作为参照物来观察动态世界->时域
类似乐谱->频域
任何周期函数都可以看作不同振幅,不同相位正弦波的叠加
不同频率的正弦波成为频率分量
频域中0频率被称为直流分量,级数叠加中,仅仅影响全部波形相对数轴整体向上或向下而不改变的形状
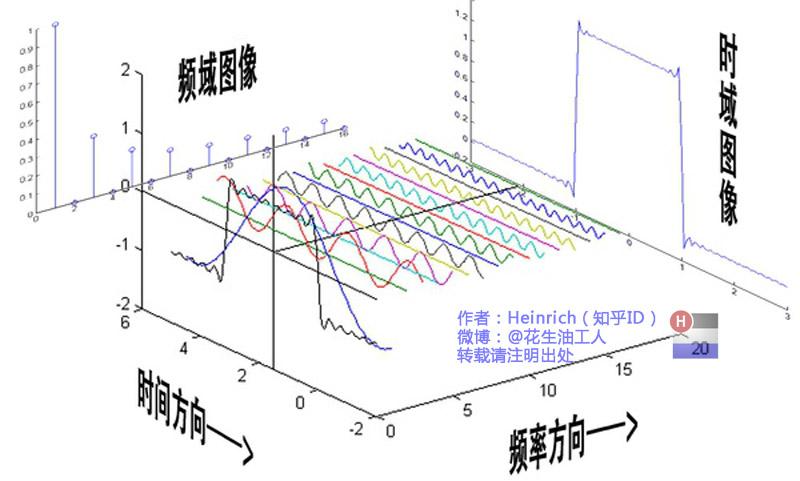
从某条曲线中去除一些特定的频率成分,称为滤波
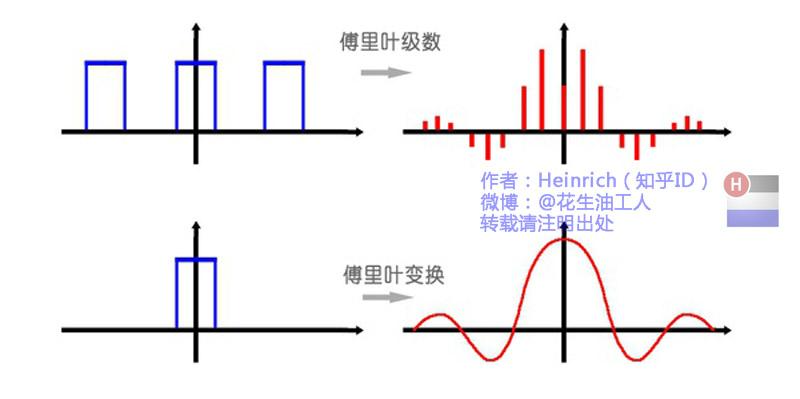
级数:周期连续->非周期离散
变换:非周期连续(时域)->非周期连续(频域)
用cv2.dft()进行时域变换到频域
用cv2。idft()进行频域变换到时域
得到的结果中频率为0的部分会出现在左上角,通过shift变换来实现
cv2.dft()返回的结果是双通道的(实部、虚部),通常还需要转换成图像格式才能展示(0,255)
全卷积神经网络(FCN)
FCN中的主要特点是大量使用卷积、上采样和跳跃连接
传统的卷积神经网络通常在网络的最后一层使用全连接层,将原始的二维矩阵压缩 成一维矩阵,导致空间特征信息的丢失,因此,卷积层替换掉全连接层是行之有效的方法。影像的目标提取及输出应该是一个正常的特征映射,即在不考虑大小的情况下应当是二维的。
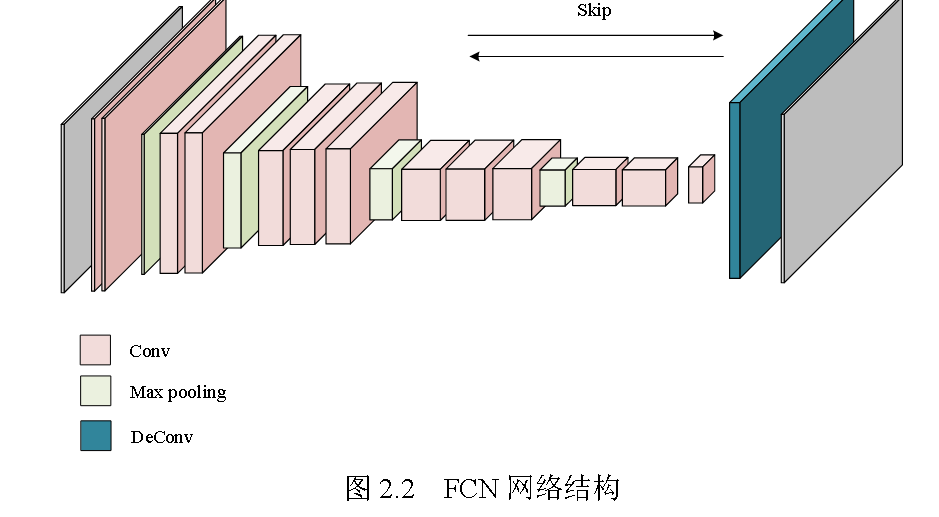
为了降低高分辨率遥感影像中细节信息的损失,采用了跳跃连接结构。对于神经网络,浅层网络有丰富的高分辨率特征映射,而深层网络有低分辨率的特征 映射,但是拥有更多抽象的语义信息。跳跃连接结构可以在各个层次之间,混合浅层的网络细节信息内容与深度的网络语义信息内容并通过特征拼接,改善提取 结果。全卷积神经网络,是在网络的最后阶段通过上采样可以恢复特征图到原始尺寸。
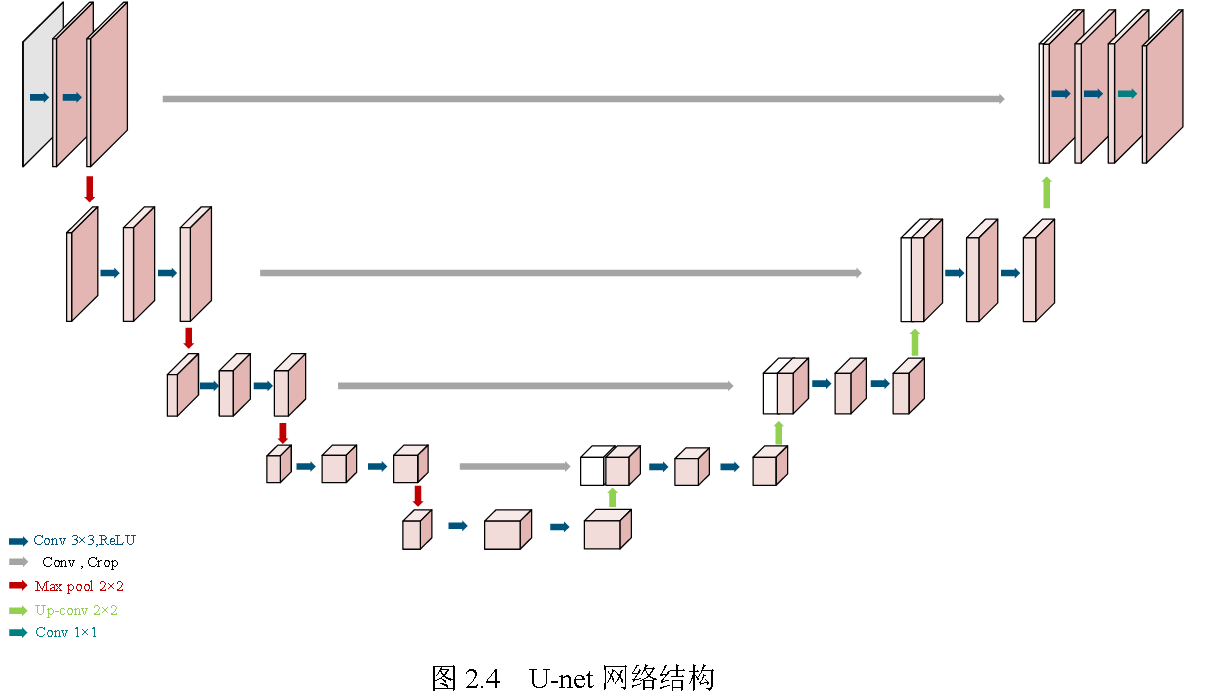
U-net模型是2015年由 Ronneberger 等人提出的一种改进的全卷积神经 网络,最初应用于医学图像的分割。U-net 网络结构如图 2.4 所示,包括五个分 辨率标度,由收缩路径和扩展路径组成。其中,跳跃连接结构可以恢复在收缩路 径中损失的高分辨率图像细节信息。
空洞卷积
在语义分割网络中通常会使用池化操作来减小特征图的大小尺寸,起到减少参数量和增大感受野的作用。但是会出现一些不可控的问题,在池化过程中会导 致特征信息丢失,而后进行的上采样操作并不能补足丢失的特征信息,特别是对于小型目标特征,进而导致特征提取效果不佳。在这些问题的基础上,空洞卷积 提出可以很好避免这些现象。空洞卷积是针对普通卷积感受野的限制性进行了改进,在普通卷积核中利用空洞率作为一个超参数,实现感受野的指数级扩展,却不会丢失分辨率和特征覆盖范围。
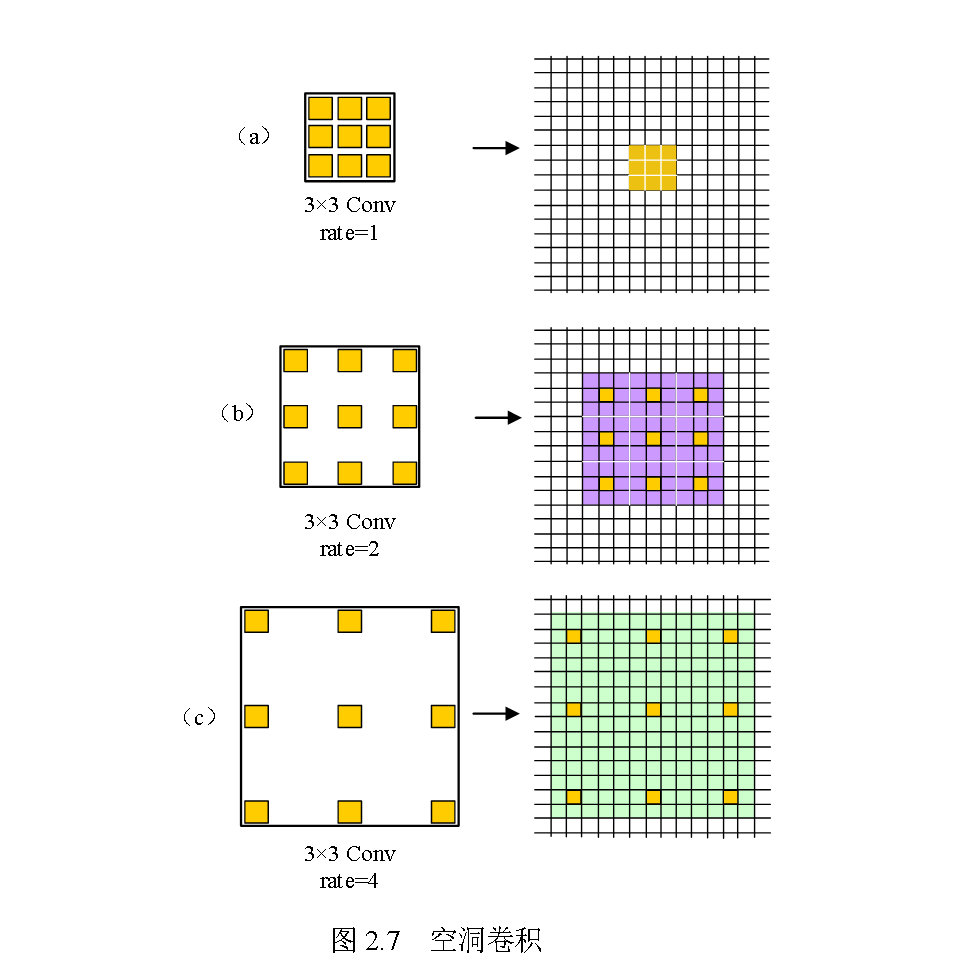
空洞卷积引入了新的参数膨胀率
空洞卷积对卷积核间隔采样,间隔大小通过膨胀率来控制
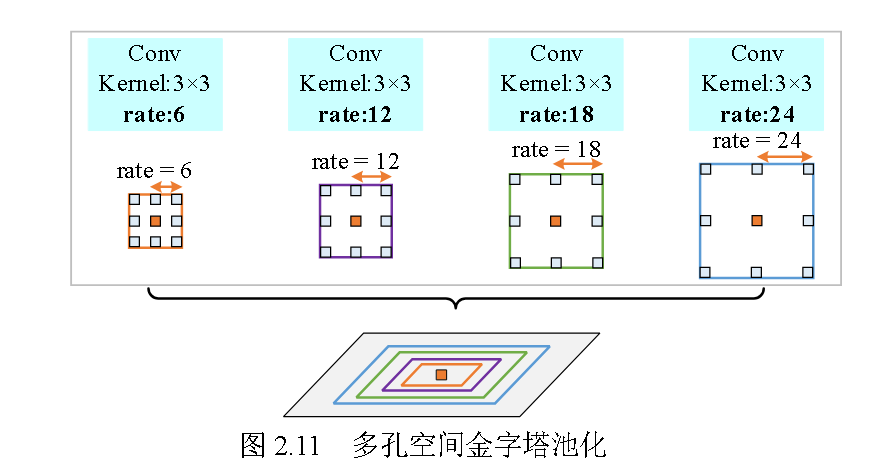
多孔空间金字塔
RoadTracer
文章:RoadTracer: Automatic Extraction of Road Networks from Aerial Images
顶会:CVPR2018
使用卷积神经网络(CNNs)来检测哪些像素属于一条道路(分割)
,然后利用复杂的后处理来将这些像素转化成路网,但这些分割方法具有较高的错误率,因为噪声CNN输出是难以纠正的
自动构建精确的道路网络图的新方法——道路跟踪器
即道路跟踪器使用基于CNN的决策函数引导的迭代搜索过程直接从CNN的输出导出道路网络图。每次迭代时都使用CNN决策网络判断是否将一部分路网加入到已经创建的路网中

RoadTracer的核心算法流程。首先给定一个路网的起点v0和包围盒(需要提取路网的区域),然后RoadTracer会维护一个顶点栈和一个路网。每次从栈顶取一个顶点,并在其基础上寻找下一个与其相连的顶点。如果找到下一个顶点(潜在),则将其加入栈顶,同时更新路网;反之就将该顶点从栈顶弹出。当栈为空时,则表明该图像上的所有路网信息已经完全获取。
迭代搜索算法
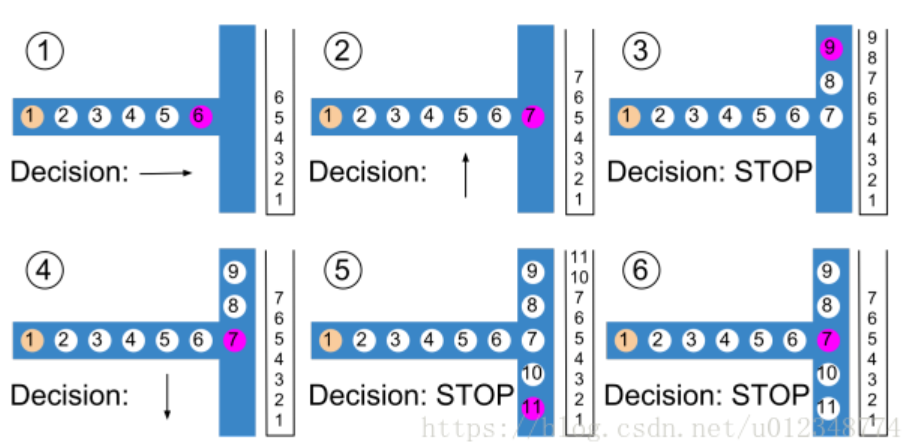
下图展示了RoadTracer在路口的运行方式。首先从顶点1开始逐步往前到顶点6,此时栈也逐步增加;在路口先向上(默认设定)寻找新的顶点,并最终到顶点9;由于顶点9后再无新的顶点,因此栈又逐步减少,最后又回到顶点7;然后再向下寻找到顶点11;最终由于顶点11后无新的顶点,栈又回到了顶点7。最后如果没有新的顶点,栈会逐步被清空,从而完成路网的检测。
CNN决策网络
CNN决策网络输入层是一个在顶点上d×d大小的窗口,该窗口总共有4层,前3层是图像信息,最后一层是矢量化后的路网信息;因此能够保证决策网络能够获取当前顶点所在区域足够的的信息。 CNN决策网络的输出层包括两部分,分别是行动信息和角度信息。行动信息包括停止和运动,角度信息是运行的方法。

转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 jaytp@qq.com

