Dansenet
DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用
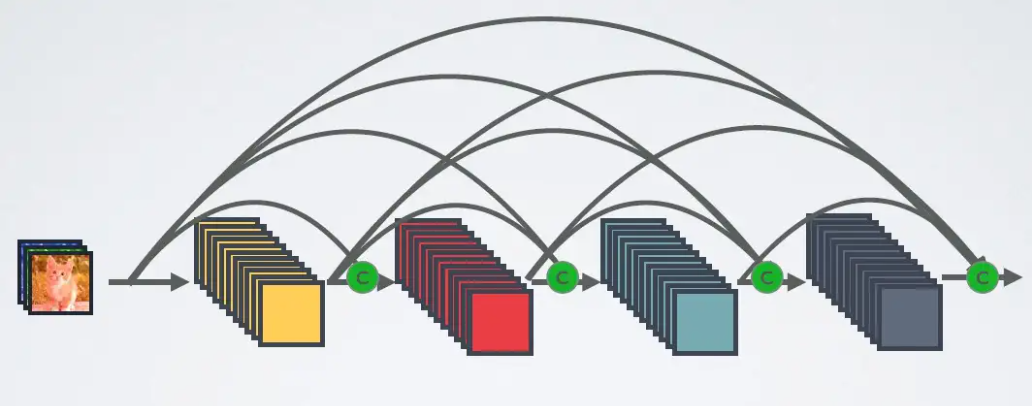
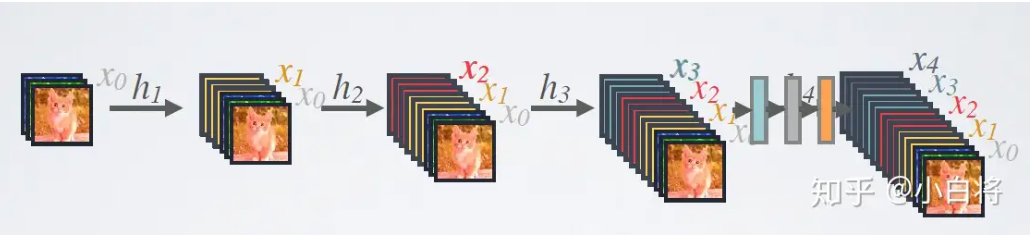
DenseNet的前向过程如图3所示,可以更直观地理解其密集连接方式,比如 h3 的输入不仅包括来自 h2 的 x2 ,还包括前面两层的 x1 和 x2 ,它们是在channel维度上连接在一起的。
DenseNet的网络结构主要由DenseBlock和Transition组成
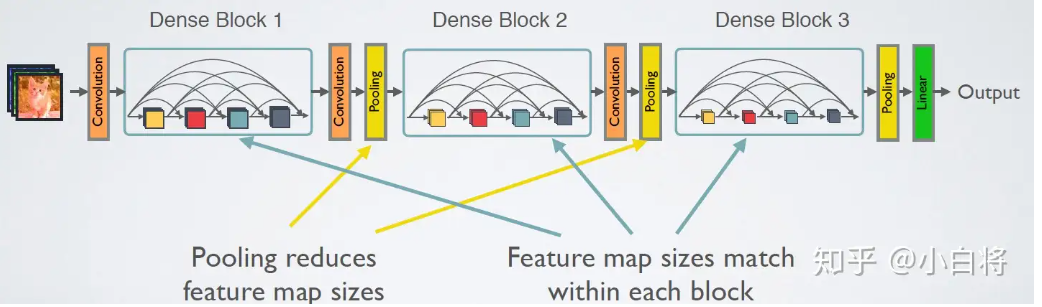
由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量,主要是原有的结构中增加1x1 Conv,如图7所示,即BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv,称为DenseNet-B结构。其中1x1 Conv得到 4k 个特征图它起到的作用是降低特征数量,从而提升计算效率。
Transition层可以起到压缩模型的作用。假定Transition的上接DenseBlock得到的特征图channels数为 m ,Transition层可以产生 ⌊θm⌋ 个特征(通过卷积层),其中 θ∈(0,1] 是压缩系数(compression rate)。当 θ=1 时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,文中使用 θ=0.5 。对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。
LinkNet
大多数的现有的语义分割技术使用的是encoder-decoder的结构。Encoder将信息编码到特征空间,解码器将这些信息映射到类别空间用来分割表示
像YOLO,Fast RNN,SSD专注于实时对象检测,但在语义分割上几乎没有任何工作
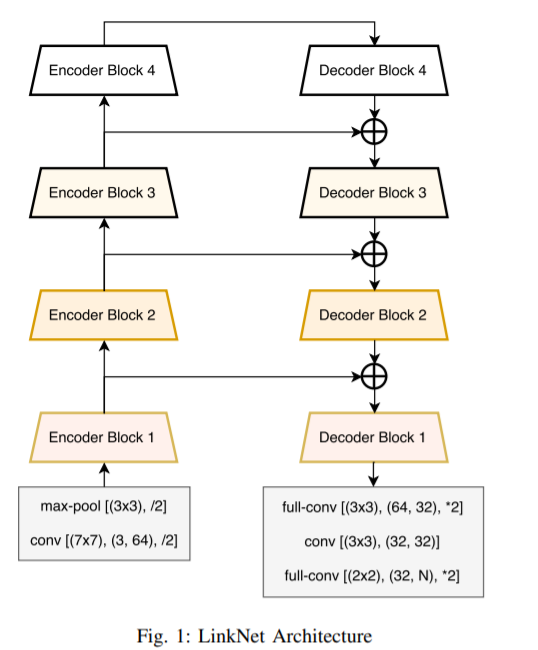
LinkNet的结构看图就已经很清楚了,将每一层编码器的结果保存一份,再在解码器解出的结果和对应的编码结果加和,传入下一层解码器中去。
import torch
import torch.nn as nn
import torchvision.models as model
class Decoder(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, output_padding=0, bias=False):
super(Decoder, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_planes, in_planes // 4, 1, 1, 0, bias=bias),
nn.BatchNorm2d(in_planes // 4),
nn.ReLU(inplace=True)
)
self.tp_conv = nn.Sequential(
nn.ConvTranspose2d(in_planes // 4, in_planes // 4, kernel_size, stride=stride, padding= padding, output_padding= output_padding, bias= bias),
nn.BatchNorm2d(in_planes // 4),
nn.ReLU(True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_planes // 4, out_planes, 1, 1, 0, bias=bias),
nn.BatchNorm2d(out_planes),
nn.ReLU(True)
)
def forward(self, x):
x = self.conv1(x)
x = self.tp_conv(x)
x = self.conv2(x)
return x
class LinkNet(nn.Module):
def __init__(self, n_classes=21):
super(LinkNet, self).__init__()
base = model.resnet18(pretrained=True)
self.in_block = nn.Sequential(
base.conv1,
base.bn1,
base.relu,
base.maxpool
)
self.encoder1 = base.layer1
self.encoder2 = base.layer2
self.encoder3 = base.layer3
self.encoder4 = base.layer4
self.decoder1 = Decoder(64, 64, 3, 1, 1, 0)
self.decoder2 = Decoder(128, 64, 3, 2, 1, 1)
self.decoder3 = Decoder(256, 128, 3, 2, 1, 1)
self.decoder4 = Decoder(512, 256, 3, 2, 1, 1)
self.tp_conv1 = nn.Sequential(
nn.ConvTranspose2d(64, 32, 3, 2, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(True)
)
self.tp_conv2 = nn.ConvTranspose2d(32, n_classes, 2, 2, 0)
def forward(self, x):
x = self.in_block(x)
e1 = self.encoder1(x)
e2 = self.encoder2(e1)
e3 = self.encoder3(e2)
e4 = self.encoder4(e3)
d4 = e3 + self.decoder4(e4)
d3 = e2 + self.decoder3(d4)
d2 = e1 + self.decoder2(d3)
d1 = x + self.decoder1(d2)
out = self.tp_conv1(d1)
out = self.conv2(out)
out = self.tp_conv2(out)
return out
if __name__ == "__main__":
inputs = torch.randn((1, 3, 352, 480))
net = LinkNet(n_classes=12)
out = net(inputs)
print(out.size())
D-LinkNet网络结构
图像分割在卫星遥感道路分割领域大致有以下一系列算法,算法发布时间线如下: FCN(2015)->UNet(2015) -> LinkNet(2017)->D-LinkNet(2018)->NL-LinkNet(2019)->…
D-LinkNet的网络结构如下图所示:
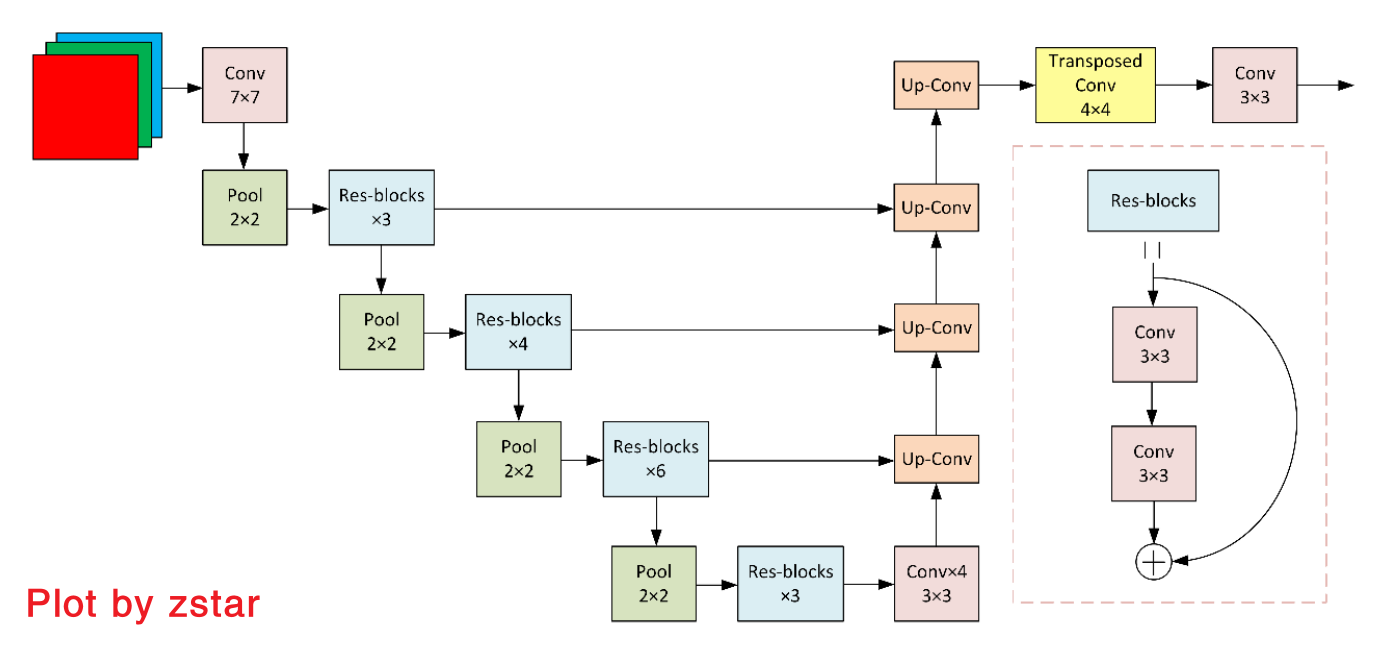
这个网络整体结构和UNet比较类似,主要在此架构中加了一些小改进,如残差块、空洞卷积等。改进提升比较明显的是该算法引入了TTA(Test Time Augmentation)策略,即测试时加强
TTA策略
TTA的思想就是在测试时使用数据增强,比如一张图片直接进行分割,得到的效果可能有限,那么将这副图片进行旋转、翻转等数据增强方式,进行分割,最后将所有分割结果进行叠加。
首先,程序加载完一张图片后,img是原图,img90是将图像逆时针旋转90度,相关代码:
def segment(self, path):
img = cv2.imread(path)
img = cv2.resize(img, resize_settings) # Shape:(1024, 1024, 3)
img90 = np.array(np.rot90(img)) # Shape:(1024, 1024, 3)
img1 = np.concatenate([img[None, ...], img90[None, ...]]) # Shape:(2, 1024, 1024, 3) img[None]:增加第一个位置维度
img1是将这两张图片拼接起来,下面直观进行显示查看:
show_img(img1[0], img1[1])

之后,构建了一个img2,在img1的第二个维度进行逆序,实现垂直翻转
img2 = np.array(img1)[:, ::-1] # 垂直翻转
show_img(img2[0], img2[1])

后面就是对每一个部分进行推理,然后最后返回的mask2是叠加后的结果,maska[0]是原始图像的推理结果
maska = self.net.forward(img1).squeeze().cpu().data.numpy() # img1:Shape:(2, 1, 1024, 1024) -> (2, 1024, 1024)
maskb = self.net.forward(img2).squeeze().cpu().data.numpy()
maskc = self.net.forward(img3).squeeze().cpu().data.numpy()
maskd = self.net.forward(img4).squeeze().cpu().data.numpy()
mask1 = maska + maskb[:, ::-1] + maskc[:, :, ::-1] + maskd[:, ::-1, ::-1]
mask2 = mask1[0] + np.rot90(mask1[1])[::-1, ::-1]
直观进行比较,左侧是原图推理,右侧是TTA后的推理结果:
show_img(maska[0], mask2)

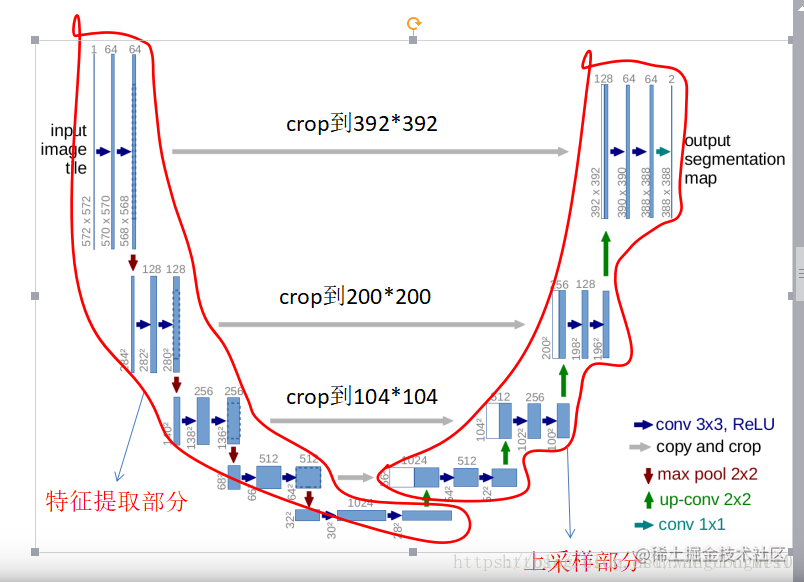
Unet
一种U型的网络结构来获取上下文的信息和位置信息
这个结构就是先对图片进行卷积和池化,在Unet论文中是池化4次,比方说一开始的图片是224x224的,那么就会变成112x112,56x56,28x28,14x14四个不同尺寸的特征。然后我们对14x14的特征图做上采样或者反卷积,得到28x28的特征图,这个28x28的特征图与之前的28x28的特征图进行通道伤的拼接concat,然后再对拼接之后的特征图做卷积和上采样,得到56x56的特征图,再与之前的56x56的特征拼接,卷积,再上采样,经过四次上采样可以得到一个与输入图像尺寸相同的224x224的预测结果。
其实整体来看,这个也是一个Encoder-Decoder的结构:
- FCN是通过特征图对应像素值的相加来融合特征的;
- U-net通过通道数的拼接,这样可以形成更厚的特征,当然这样会更佳消耗显存;
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 jaytp@qq.com

